
In questo articolo, “Tuple, liste e dizionari in Python” ci occupiamo delle caratteristiche di tuple, liste e dizionari: tre tipi di dato strutturato. Studieremo la loro definizione e la loro manipolazione
Introduzione
L’andamento della temperatura misurata ogni ora nell’arco della giornata può essere rappresentato mediante un grafico:
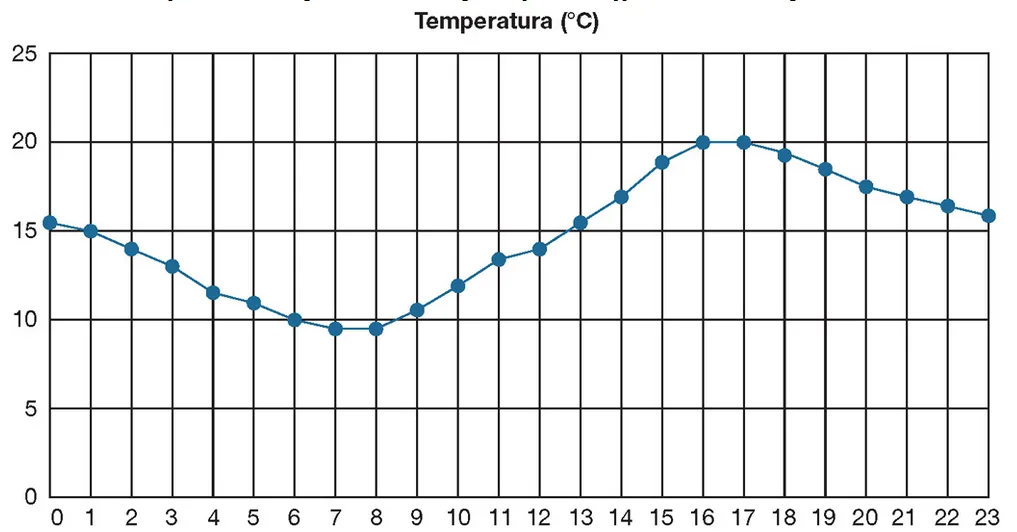
I dati sulla base dei quali il grafico viene tracciato possono essere rappresentati con una tabella:

L’elaborazione di questi dati (per esempio per determinarne il valore medio, minimo o massimo) richiederebbe 24 diverse variabili, rendendo il codice del programma, o della funzione, di elaborazione difficile da scrivere e da interpretare. Dato che sequenze di dati di questo tipo sono molto comuni, arrivando talvolta a sequenze di migliaia o di milioni di valori, tutti i linguaggi di programmazione ne prevedono la gestione mediante una variabile aggregata, i cui singoli valori sono identificati dalla posizione nella sequenza: questo tipo di variabile aggregata è definito vettore o array monodimensionale; il valore della posizione di un valore è denominato indice.
I tipi di dato strutturato: caratteristiche e diversità
Con il termine tipi di dato strutturato vengono riferiti i tipi di dato che organizzano un insieme di valori permettendone la gestione mediante una singola entità aggregata.
In Python sono previste più tipologie di dati strutturati e, per ognuna di esse, sono presenti funzionalità per la selezione e la manipolazione delle informazioni contenute. Alcuni tra i tipi strutturati fondamentali sono mostrati nella tabella:

Come mostrato nella tabella, alcune caratteristiche che, in generale, sono utilizzate per classificare le collezioni rappresentabili dai tipi di dato strutturato sono le seguenti:
Copied!la possibilità di contenere dati di tipologia diversa, nel caso di collezioni eterogenee, oppure della stessa tipologia, nel caso di collezioni omogenee; la presenza o meno di un ordinamento, ossia di un’associazione univoca tra ogni elemento della struttura e una posizione; la possibilità o meno di contenere elementi uguali; l’ammissibilità o meno di modifiche agli elementi della collezione, o al loro numero.
Occorre tenere in considerazione ognuna di queste caratteristiche per scegliere il tipo di dato strutturato più adeguato alla specifica esigenza del contesto da modellizzare.
Per esempio:
Copied!problemi che necessitano di sequenze di valori non soggette a modifiche (per esempio i giorni della settimana o i mesi di un anno) possono essere modellati mediante l’uso di tuple, essendo queste assimilabili a un elenco non modificabile di elementi eterogenei con la possibilità di poter accedere a ogni elemento conoscendone la posizione; la necessità di interagire con l’utente, per esempio per conoscere i prodotti da acquistare al supermercato o gli impegni previsti per la giornata richiede l’uso di una struttura dati modificabile durante la fase di acquisizione dati, per questo motivo la scelta del tipo di dato lista potrebbe risultare vantaggiosa.
OSSERVAZIONE Dagli esempi proposti è possibile desumere l’assenza di un tipo di dato migliore degli altri e utilizzabile in qualsiasi contesto, esistono, invece, di volta in volta, scelte più adeguate di altre per specifiche richieste.
I tipi di dato strutturato non modificabili di Python
I tipi di dato non modificabili in Python rappresentano collezioni in cui non è permesso né variare il numero di elementi, né sostituire elementi con altri.
Alcune caratteristiche di questa famiglia di tipi di dato sono la possibilità di accedere direttamente a un elemento conoscendone la posizione e di selezionare sottosequenze appartenenti alla collezione.
Le Tuple
Le tuple in Python sono sequenze ordinate di elementi che possono appartenere anche a tipi diversi e che ammettono duplicati, in cui non è possibile sostituire elementi con altri:
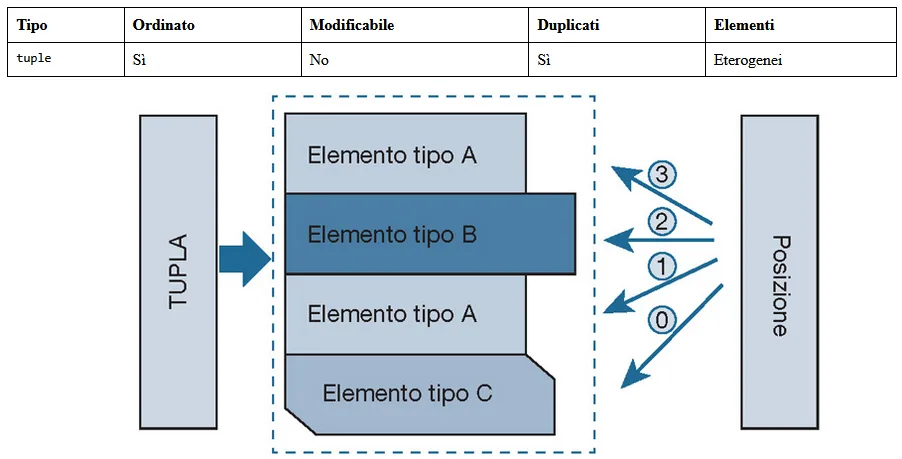
Sono definite fornendo una sequenza di elementi separati da «,» e, anche se non obbligatorio, racchiusi tra i simboli «(» e «)».
La definizione di una tupla è permessa anche utilizzando la funzione tuple(), che richiede come argomento una sequenza di valori fornita esplicitamente, o tramite una variabile di tipo strutturato
Le seguenti porzioni di codice creano delle tuple e ne visualizzano il contenuto.
Tuple vuote
t1 = ()
print(t1)
t2 = tuple()
print(t2)
risultato:
()
()
Tuple di valori numerici
t1 = (1, 2, 3)
print(t1)
t2 = 1, 2, 3
print(t2)
risultato:
(1, 2, 3)
(1, 2, 3)
Tuple di tipi eterogenei
t = (1, "Python", 2.3)
print(t)
risultato:
(1, 'Python', 2.3)
Creazione mediante oggetti iterabili: tupla, range e stringa
t1 = tuple((1, 2, 3))
print(t1)
t2 = tuple(range(1, 4))
print(t2)
t3 = tuple("Python")
print(t3)
risultato:
(1, 2, 3)
(1, 2, 3)
(‘P’, ‘y’, 't', 'h', 'o', 'n')La selezione degli elementi
La tupla è una sequenza ordinata, infatti gli elementi in essa contenuti sono ordinati in base a un indice che ne identifica la posizione all’interno della collezione.
È possibile accedere agli elementi che costituiscono la tupla specificando tra i simboli «[» e «]» la posizione occupata all’interno della sequenza.
Il primo elemento ha posizione 0 e l’uso di un indice di posizione non valido restituisce un errore di tipo IndexError.
Sono ammesse anche posizioni negative; in tal caso -1 corrisponde all’ultimo elemento, -2 al penultimo e così via. Gli indici non validi sono, quindi, quelli positivi maggiori del numero degli elementi della tupla e quelli negativi il cui valore assoluto è maggiore del numero degli elementi della tupla.
ESEMPIO
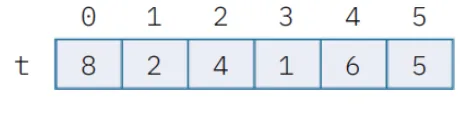
Data la tupla contenente i primi 6 numeri primi
t = (1, 3, 5, 7, 11, 13)
una sua possibile rappresentazione è quella riportata in figura:
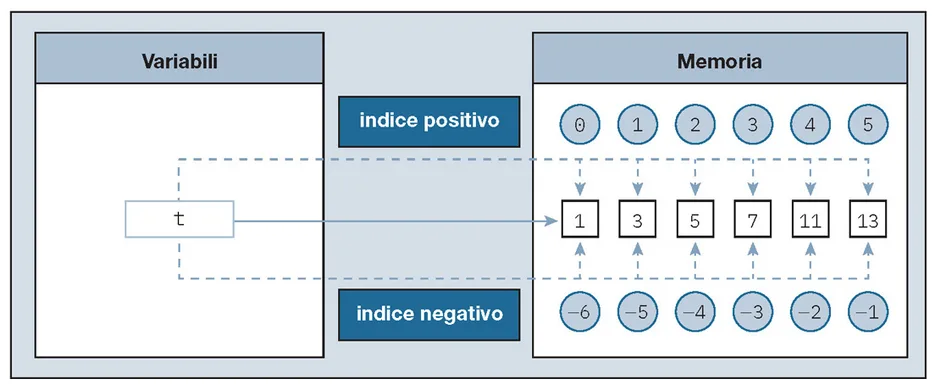
Per cui selezionando le posizioni 0, 1, 5, -1 e -3 con la sintassi t[0], t[1], t[5], t[–1], t[–3] saranno restituiti gli elementi: 1, 3, 13, 13, 7.
È necessario fare attenzione alla differenza che c’è tra la posizione (identificata dall’indice) di un elemento della tupla e il suo contenuto
ESEMPIO: Prendiamo in considerazione le due seguenti espressioni
t[3] + 1
t[3 + 1]dove t è la seguente tupla:
t[3] + 1 restituisce 1+1 = 2
t[3 + 1] restituisce t[4] = 6La lunghezza di una tupla è determinata dal numero dei suoi elementi e non può variare durante l’esecuzione del programma; è possibile conoscere la lunghezza mediante la funzione integrata in Python len().
t = tuple((1,2,3))
print(len(t)) #stampa 3La nidificazione di tuple
In caso di tuple nidificate, in cui un elemento di una tupla è una tupla a sua volta, l’accesso agli elementi può avvenire tramite l’uso di indici multipli. Per esempio, per rappresentare una matrice m bidimensionale si può ricorrere a una tupla di tuple; con la notazione m[i][j] viene ritornato l’elemento che si trova alle coordinate (i, j), ovvero all’incrocio tra la (i + 1)-esima riga e la (j + 1)-esima colonna, visto che gli indici in Python iniziano da 0.
- Per individuare un elemento di una sequenza multidimensionale sarà necessario specificare tanti indici quante sono le dimensioni della sequenza.
Nel caso di una matrice composta da n righe ed m colonne, si usa dire che questa è di dimensione n × m; se i due valori n ed m sono uguali, la matrice viene detta quadrata.
ESEMPIO: La seguente è una matrice di 15 elementi organizzata su 3 righe e 5 colonne:
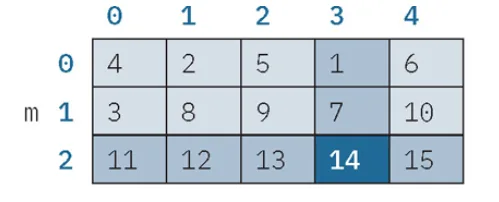
Con la notazione m[2][3] viene individuato l’elemento che si trova alle coordinate (2, 3), ovvero all’incrocio tra la terza riga e la quarta colonna (dato che la numerazione sia delle righe sia delle colonne parte dall’indice 0) il cui contenuto e il valore 14.
La scansione degli elementi di una matrice, per esempio per la visualizzazione del loro contenuto, può essere fatta con due cicli for nidificati
ESEMPIO: Il seguente frammento di codice definisce la tupla nidificata che rappresenta la matrice di valori dell’esempio precedente e ne visualizza il contenuto:
m = ((4, 2, 5, 1, 6), (3, 8, 9, 7, 10), (11, 12, 13, 14, 15))
for i in range(3):
for j in range(5):
print(m[i][j], end = "\t")
print()
#stmperà:
# 4 2 5 1 6
# 3 8 9 7 10
# 11 12 13 14 15 La matrice viene visualizzata per righe, nel senso che per ogni singola riga vengono visualizzati i valori delle varie colonne. Invertendo l’ordine dei due cicli for la matrice verrà visualizzata per colonne:
m = ((4, 2, 5, 1, 6), (3, 8, 9, 7, 10), (11, 12, 13, 14, 15))
for j in range(5):
for i in range(3):
print(m[j][i], end = "\t")
print()
#stmperà:
# 4 3 11
# 2 8 12
# 5 9 13
# 1 7 14
# 6 10 15 Lo spacchettamento
Data una tupla è possibile assegnare i suoi elementi a singole variabili eseguendo quella che è conosciuta come l’operazione di spacchettamento.
È possibile, quindi, spacchettare una qualsiasi tupla assegnandola a una lista di variabili separate da «,» e di numero uguale al numero di elementi della sequenza (in caso contrario sarà restituito un errore di tipo ValueError).
ESEMPIO: La seguente tupla rappresenta un colore mediante 2 elementi: un nome e una sequenza di tre valori indicanti l’intensità di rosso, verde e blu della codifica RGB necessari per generarlo:
colore = ("Bianco", (255, 255, 255))
#È possibile spacchettare la tupla in due variabili come segue:
colore_nome, colore_rgb = ("Bianco", (255, 255, 255))
#Le istruzioni:
print(colore_nome)
print(colore_rgb)
#visualizzeranno il seguente output:
Bianco
(255, 255, 255)La manipolazione delle tuple
Esiste un’alternativa alla navigazione del contenuto di una tupla mediante l’utilizzo di costrutti iterativi ed è realizzata mediante la funzione enumerate. Questa funzione è integrata in Python e permette l’accesso contemporaneo sia agli indici sia ai valori degli elementi di una tupla. La sua invocazione richiede come parametro un tipo di dato iterabile (quindi anche una tupla) e crea una sequenza composta da tuple contenenti l’indice e il valore dell’elemento di partenza come esemplificato nell’esempio seguente.
ESEMPIO: Data la tupla
colori = ("Rosso", "Arancione", "Giallo", "Verde", "Blu", "Indaco", "Viola", "Azzurro", "Marrone", "Celeste")il seguente frammento di codice
for indice, valore in enumerate(colori):
print(indice, ":", valore)visualizza il seguente output:
0 : Rosso
1 : Arancione
2 : Giallo
3 : Verde
4 : Blu
5 : Indaco
6 : Viola
7 : Azzurro
8 : Marrone
9 : CelesteAnalogo risultato è generato dalle seguenti istruzioni:
for i in range(len(colori)):
print(i, ":", colori[i])Dal momento che le tuple sono un tipo di dato non modificabile, la necessità di modificare il loro contenuto, per esempio aggiungendo elementi, può essere soddisfatta solo creando una nuova tupla e associando a essa il precedente identificatore.
ESEMPIO:
t = (1, 2, 3)
t = (1, 2, 3, 4, 5)In aggiunta alla selezione di un singolo elemento della tupla, Python permette anche la selezione di sottosequenze di elementi. Quest’operazione è nota con il nome di slicing e ha la seguente sintassi
<tupla_origine>[<pos_iniziale> : <pos_finale> : <passo>]
dove:
-
<pos_iniziale>specifica l’indice di inizio selezione (incluso), se omesso l’inizio coincide con il primo elemento della tupla; -
<pos_finale>specifica l’indice di fine selezione (escluso), se omessopos_finalecoincide con la lunghezza della tupla; -
<passo>specifica l’incremento da usare per selezionare solo alcuni elementi dell’intervallo, se omesso forza un incremento di una posizione non generando quindi salti nella selezione degli elementi.
ESEMPIO: Con riferimento alla tupla
colori = ('rosso', 'verde', 'blu', 'giallo', 'viola', 'nero', 'rosa')le seguenti istruzioni ne selezionano sottosequenze e visualizzano il risultato:
slice_tupla_1 = colori[2 : 5]
print(slice_tupla_1)risultato: ('blu', 'giallo', 'viola')Il seguente elenco mostra gli operatori e le funzioni principali applicabili alle tuple con un esempio di applicazione per evidenziare il loro utilizzo e la loro invocazione.
Iterazione degli elementi di una tupla.
t = (1, 2, 3)
for i in t:
print(i)
visualizza:
1
2
3
Verifica dell’appartenenza di un elemento alla tupla.
Si realizza mediante l’utilizzo di appartenenza in.
ESEMPIO: La seguente porzione di codice controlla se la tupla t contiene il valore numerico 2 e visualizza il risultato:
t = (1, 2, 3)
num = 2
if(num in t):
print(num, "presente in", t)
La sua esecuzione genera il seguente output:
2 presente in (1, 2, 3)
Concatenazione di tuple. Si realizza mediante operatore «+»
ESEMPIO
La seguente porzione di codice crea una tupla come risultato della concatenazione di due tuple.
t1 = (1, 2)
t2 = ("tre", "quattro")
t = t1 + t2
L’istruzione
print(t)
visualizza:
(1, 2, 'tre', 'quattro')
Ripetizione di tuple. Si realizza mediante operatore «*».
ESEMPIO
La seguente porzione di codice crea una tupla come risultato della ripetizione di una tupla.
t1 = (1, 2)
t = t1 * 3
L’istruzione
print(t)
visualizza:
(1, 2, 1, 2, 1, 2)
Ottenimento del numero di elementi della tupla. Ottenibile mediante la funzione len(...) integrata nel linguaggio.
ESEMPIO
t = (1, "due", "tre", 4, 5, 6)
l’istruzione
print(len(t))
visualizza il numero di elementi della tupla:
6
Selezione di un elemento.
ESEMPIO
t = (1, "due", "tre", 4, 5, 6)
queste istruzioni selezionano rispettivamente gli elementi di indice 1 e 6
print(t[1])
print(t[6])
e generano i seguenti risultati:
'due'
IndexError: tuple index out of range
Selezione di una sottosequenza. Ottenibile mediante operazione di slicing.
ESEMPIO
t = (1, "due", "tre", 4, 5, 6)
la seguente istruzione seleziona gli elementi in posizione 1 e 3
print(t[1: 4: 2])
e li visualizza:
('due', 4)
Individuazione dell’elemento minore e maggiore della tupla. Le funzioni min e max, integrate nel linguaggio, restituiscono rispettivamente l’elemento minore e maggiore di una sequenza di valori se gli elementi sono comparabili.
ESEMPIO
La seguente porzione di codice
t = ("a", "b", "c", "d")
print(max(t))
restituisce l’elemento della tupla t con valore maggiore:
D
Nel seguente caso
t = ("a", "b", 3, 4)
print(max(t))
la ricerca del massimo restituisce un errore perché gli elementi non sono comparabili tra loro:
TypeError: '>' not supported between instances of 'int' and 'str'
Posizione della prima occorrenza di un elemento.vMediante il metodo index(e) del tipo di dato tupla viene restituito l’indice della prima occorrenza dell’elemento e nella tupla.
ESEMPIO
La seguente porzione di codice ricerca e visualizza l’indice della prima occorrenza dell’elemento 'tre' nella tupla t:
t = (1, "due", "tre", 4, 5, 6)
print(t.index('tre'))
Il risultato generato è:
2
Numero di occorrenze di un elemento. Ottenuto mediante il metodo count del tipo di dato tupla.
ESEMPIO
Data la tupla
t = (1, "due", "tre", 4, 1, 5, 6)
la seguente istruzione conta le occorrenze dell’elemento 1 nella tupla t e visualizza il risultato:
print(t.count(1))
2Per quanto riguarda le stringhe si faccia riferimento all’articolo dedicato al seguente link: https://profgiagnotti.it/i-numeri-e-le-stringhe/
I tipi di dato strutturato modificabili
I tipi di dato strutturato modificabili consistono in sequenze di dati in cui oltre alle funzionalità condivise con i tipi di dato non modificabili è permessa anche l’aggiunta, la rimozione e la modifica degli elementi della collezione; il naturale campo di applicazione di un tipo di dato appartenente a questa categoria è la rappresentazione di dati mutevoli, in contesti dove il loro valore e la loro quantità non sono noti a priori ma acquisiti durante l’esecuzione o l’interazione con l’utente.
Le liste
Le liste sono sequenze ordinate e modificabili di elementi non necessariamente dello stesso tipo
Sono create fornendo una sequenza di elementi separati da «,» e racchiusi dai simboli «[» e «]». La creazione di una lista è possibile anche utilizzando la funzione list() che richiede come parametro un oggetto iterabile.
ESEMPIO
Le seguenti porzioni di codice creano delle liste e ne visualizzano il contenuto:
liste vuote:
li1 = []
li2 = list()
print(li1, li2, sep = '\n')
[]
[]
lista di valori numerici:
li = [1, 2, 3]
print(li)
[1, 2, 3]
liste di tipi eterogenei:
li = [1, "Python", 2.3]
print(li)
[1, ‘Python’, 2.3]
creazione mediante oggetti iterabili: tupla, range e stringa:
li1 = list((1, 2, 3))
li2 = list(range(1, 4))
li3 = list("Python")
print(li1)
print(li2)
print(li3)
[1, 2, 3]
[1, 2, 3]
['P', 'y', 't', 'h', 'o', 'n']Alle liste si applicano le funzionalità già illustrate per i tipi non modificabili come, per esempio, l’operatore ripetizione «*», le funzioni min() e max() e i metodi index() e count() per indentificare rispettivamente la posizione della prima occorrenza e il numero di ripetizioni di un elemento.
Selezione e modifica degli elementi
Le liste sono un tipo di dato ordinato quindi è possibile accedere a un elemento della collezione mediante il suo indice e l’operatore di selezione «[]» e, conseguenza di questo, sono lecite anche tutte le possibili formulazioni dell’operazione di slicing.
ESEMPIO: Considerata la lista
vocali = ['a', 'e', 'i', 'o', 'u']
riportiamo nella tabella alcuni risultati dell’applicazione degli operatori di selezione e slicing.
Poiché le liste sono un tipo di dato modificabile, è possibile assegnare o rimuovere elementi utilizzando l’operatore di selezione e l’operatore di assegnazione.
È possibile anche effettuare aggiornamenti multipli selezionando una porzione della lista (mediante l’operazione di slicing) e sostituendola con quella desiderata.
ESEMPIO
Considerata la lista
vocali = ['a', 'e', 'i', 'o', 'u']
la seguente sequenza di assegnamenti esemplifica l’utilizzo dell’operatore di selezione e slicing per la modifica degli elementi di una lista.
vocali[1] = '1'
print(vocali)
vocali[0] = vocali[1]
print(vocali)
vocali[2 : 4] = ['2', '2', '2']
print(vocali)
vocali[2 : 4] = ['3', '3']
print(vocali)
vocali[0 : 4 : 2] = ['4']
print(vocali)
Output generato da ciascun assegnamento:
['a', '1', 'i', 'o', 'u']
['1', '1', 'i', 'o', 'u']
['1', '1', '2', '2', '2', 'u']
['1', '1', '3', '3', '2', 'u']
ValueError: attempt to assign sequence of size 1 to extended slice of size 2
L’ultimo assegnamento mostra come l’operazione di slicing [i : j : k] con passo k > 1 permetta l’aggiornamento solo mediante una sequenza contenente lo stesso numero di elementi, mentre, per selezioni multiple contigue, è possibile fornire una sequenza di qualsiasi lunghezza.Le liste sono oggetti iterabili per cui possono essere visitate mediante l’utilizzo di costrutti iterativi come esemplificato negli esempi seguenti.
ESEMPIO
Il seguente frammento di codice moltiplica per 3, somma 1 agli elementi dispari di una sequenza di valori interi e dimezza gli elementi pari:
li = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
for i in range(len(li)):
if (li[i] % 2 == 0): # pari
li[i] = int(li[i]/2)
else: # dispari
li[i] = li[i] * 3 + 1
Il seguente frammento di codice somma nella variabile s il valore di tutti gli elementi di una sequenza dopo aver moltiplicato per 3 gli elementi dispari:
li = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
s = 0
for i in range(len(li)):
if (li[i] % 2 != 0): # dispari
li[i] = li[i] * 3
for e in li:
s = s + e
Da notare la differenza tra i valori generati dai due cicli dell’ultimo esempioInserimento di elementi
Python mette a disposizione, mediante dei metodi del tipo di dato strutturato list, ulteriori meccanismi per aggiungere elementi a una lista, alternativi all’utilizzo dell’operatore di assegnamento con l’operazione di slicing.
-
append(x): aggiunge un elementoxcome ultimo elemento della lista. Per esempio, data la listaspesa = ['pasta', 'pane']dopo l’esecuzione dell’istruzionespesa.append('bibite')la lista originaria è modificata ospitando 3 elementi:

frutta = ['pere', 'banane']
spesa.append(frutta)

-
insert(i, x): inserisce l’elementoxin posizione i-esima; in analogia a quanto descritto per il metodoappend, ancheinsertaggiunge sempre un singolo elemento alla collezione senza eventualmente spacchettare e ricombinare elementi di tipo strutturato nella lista; per esempio, a seguito delle seguenti istruzioni diinsert
Copied!spesa = ['pasta', 'pane'] spesa.insert(0 , 'pesce') spesa.insert(2 , 'carne') spesa.insert(-1 , 'yogurt') spesa.insert(0 , ['biscotti', 'cereali'])
la lista di partenza si modifica come segue:
Copied!['pesce', 'pasta', 'pane'] ['pesce', 'pasta', 'carne', 'pane'] ['pesce', 'pasta', 'carne', 'yogurt', 'pane'] [['biscotti', 'cereali'], 'pesce', 'pasta', 'carne', 'yogurt', 'pane']
-
extend(x): estende la lista originaria aggiungendo una nuova sequenza al suo termine; gli elementi della sequenza aggiunta vengono spacchettati e ricombinati nella lista originaria; segue un esempio in cui la lista originaria è estesa prima con gli elementi di un’altra lista e poi con quelli di una tupla.
Copied!spesa = ['pasta', 'pane']spesa.extend([biscotti, cereali])# listaspesa.extend((latte, yogurt)) # tupla
La lista di partenza si modifica come di seguito:

Rimozione degli elementi
In Python ci sono vari modi per rimuovere uno o più elementi da una lista.
-
clear(): permette la rimozione di tutti gli elementi della lista; la seguente sequenza di istruzioni fornisce come output una lista vuota:spesa = ['pasta', 'pane']spesa.clear()print(spesa) -
pop(i): rimuove l’elemento in posizionei; la richiesta di rimozione con indice non valido (per esempio superiore al numero degli elementi) restituisce un errore; se omesso, la richiesta viene tradotta come la rimozione dell’ultimo elemento della lista.
-
remove(x): rimuove il primo elemento della lista avente lo stesso valore dell’elemento
passato come parametro.
- del<…>: questa istruzione rimuove l’elemento o la sequenza di elementi specificati dopo la parola chiave del.
I dizionari
Lavorando con le stringhe e con le liste ci siamo resi conto che identificare i valori contenuti utilizzando l’indice spesso risulta scomodo. Nella realtà abitualmente abbiamo più spesso a che fare con tabelle in cui ciascun valore ha bisogno di essere associato ad altri valori che lo definiscono, lo descrivono o lo completano proprio come in una rubrica telefonica dove cerchiamo il nome della persona per sapere indirizzo email e numero di telefono.
Per ottenere questo risultato, possiamo usare più liste parallele nelle quali i valori associati hanno lo stesso indice oppure possiamo utilizzare una struttura predefinita.
Possiamo partire da una struttura di liste parallele per introdurre il meccanismo dei dizionari. Vediamo un esempio per chiarire il problema.
Supponiamo di avere a disposizione i voti della verifica di informatica di una classe e di voler trovare i nomi degli studenti che hanno ottenuto una valutazione al di sopra della media. In questo caso utilizziamo due liste parallele per memorizzare le due informazioni associate: il voto e il nome dello studente

nome = ["Bianchi", "Rossi", "Farina", "Neri", "Arancio", "Puri", "Ferri"]
voto = [10, 4.5, 6, 7.8, 4, 6.7, 8]
# due liste parallele hanno lo stesso numero di elementi
print("valutazioni verifica di informatica")
for i in range(len(voto)):
riga = "Lo studente {} ha conseguito il voto {}"
print(riga.format(nome[i], voto[i]))
# i dati corrispondono a parità di indice
# calcolo e visualizzo la media dei voti
media = sum(voto)/len(voto)
print("media dei voti:", media)
# cerco i nomi degli studenti con voto superiore alla media
print("gli studenti con voto superiore alla media sono:")
for i in range(len(voto)):
if voto[i] > media:
print(nome[i])che produce il seguente output:

Possiamo strutturare i dati in un’unica lista composta da tante sottoliste, una per ogni studente. Ciascuna sottolista contiene il nome dello studente e il relativo voto.
Naturalmente, trasformando in questo modo il programma, non varierà la risposta nella shell:
nomeVoti = [["Bianchi", 10], ["Rossi", 4.5], ["Farina", 6],["Neri", 7.8]]
nomeVoti += [["Arancio", 4], ["Puri", 6.7], ["Ferri", 8]]
# questa è una lista di liste, ogni sottolista ha due elementi
print("valutazioni verifica di informatica")
for i in range(len(nomeVoti)):
riga = "Lo studente {} ha conseguito il voto {}"
print(riga.format(nomeVoti[i][0], nomeVoti[i][1]))
# il nome è nella sottolista con indice 0, il voto in quella con indice 1
# calcolo e visualizzo la media dei voti (non voglio usare le funzioni built in)
somma = 0
for stud in nomeVoti:
somma += stud[1]
media = somma/len(nomeVoti)
print("media dei voti:", media)
# cerchiamo i nomi degli studenti con voto superiore alla media
print("gli studenti con voto superiore alla media sono:")
for stud in nomeVoti:
if stud[1] > media:
print(stud[0])che produrrà lo stesso output.
Partiamo da questa struttura di “sottoliste parallele” e introduciamo il meccanismo dei dizionari: ciascun elemento (voce) di un dizionario è costituito da una coppia chiave-valore, dove la chiave è il “descrittore” del valore.
Un dizionario è definito da un insieme di coppie chiave-valore racchiuse tra parentesi graffe e separate con una virgola. La chiave viene definita per prima e separata dal valore con un simbolo di due punti; possiamo identificare un valore tramite la sua chiave:
Copied!dizionario = {chiave_1: valore_1, chiave_2: valore_2, . . . , chiave_n: valore_n}
Come esempio, creiamo un dizionario che raccolga le caratteristiche di un’automobile assegnando a ogni coppia di valori una chiave e il suo relativo valore
auto = {"marca": "citroën", "modello": "berlingo", "colore": "bianco", "capacità serbatoio": 60}
messaggio = "l'automobile {} {} è di colore {}"
print(messaggio.format(auto["marca"], auto["modello"], auto["colore"]))che produrrà in output:

I dizionari non sono ordinati, per cui non è possibile richiamare un determinato valore utilizzando un indice, e non ammettono chiavi duplicate.
I dizionari sono mutabili, quindi possiamo modificare il valore di una coppia (accedendo tramite la chiave), aggiungere una nuova coppia (se, per esmpio, il valore della chiave con cui stiamo effettuando l’accesso non esiste) o eliminarne una esistente.
Per sapere quanti elementi ha un dizionario possiamo usare la funzione len():
Come per le stringhe e per le liste, anche per i dizionari possiamo usare
particolari metodi.
Rimozione di elementi
- Per rimuovere l’ultimo elemento inserito in un dizionario (l’ultima coppia chiave-valore), possiamo usare il metodo popitem: dizionario.popitem()
- Se conosciamo la chiave della coppia che desideriamo rimuovere allora il metodo da usare è pop, ma se il nome della chiave che desideriamo
cancellare con questo metodo non è presente nel dizionario allora il
programma genererà un errore: dizionario.pop(chiave)
votiStud = {"studente": "Rossi",
"informatica": 7,
"storia": 8,
"matematica": 6,
"italiano": 7,
"inglese": 5}
votiStud.popitem()
print("è stata cancellata l'ultima coppia")
print(votiStud)
votiStud.pop("matematica")
print("è stata cancellata la coppia di key = matematica")
print(votiStud)che produrrà il seguente output:

Aggiornamento del valore di un elemento
- Possiamo aggiornare il valore di un elemento di un dizionario di cui conosciamo la chiave con l’assegnazione dizionario[chiave] = valore;
oppure usando il metodo update(): dizionario.update({chiave: valore})
Se la coppia con la chiave indicata esiste, viene aggiornata, altrimenti viene inserita.
Riprendiamo l’esempio precedente e aggiungiamo al dizionario votiStud un nuovo voto in matematica e uno in ginnastica. La materia “matematica” verrà aggiornata con il nuovo voto, invece per la materia “ginnastica”, che non è presente tra le chiavi, sarà aggiunto un nuovo elemento in fondo alla lista
votiStud = {"studente": "Rossi",
"informatica": 7,
"storia": 8,
"matematica": 6,
"italiano": 7,
"inglese": 5}
votiStud.update({"matematica": 7})
votiStud.update({"ginnastica": 6})
print(votiStud)Il metodo keys() restituisce tutte le chiavi presenti nel dizionario in una lista:
lista = dizionario.keys()
Il metodo values() ritorna tutti i valori presenti nel dizionario in una lista:
lista = dizionario.values()
Sullo stesso dizionario creato nell’esempio precedente utilizziamo i due metodi: keys e values. Nella shell compare nella prima riga la lista delle chiavi e nella seconda la lista dei valori
votiStud = {"studente": "Rossi",
"informatica": 7,
"storia": 8,
"matematica": 6,
"italiano": 7,
"inglese"}
listaChiavi = votiStud.keys()
listaValori = votiStud.values()
print(listaChiavi)
print(listaValori)produce in output:

Visualizzazione del valore di un elemento
- Per visualizzare il valore dell’elemento di un dizionario corrispondente a una specifica chiave, usiamo il metodo get(), analogo a valore = dizionario[chiave]:
valore = dizionario.get(chiave)
Come esempio visualizziamo il valore del voto per una materia presente nel dizionario (italiano) e per una materia non presente nel dizionario. Con questo metodo riusciamo a capire se la key non è presente senza che il programma la inserisca per default:
votiStud = {"studente": "Rossi",
"informatica": 7,
"storia": 8,
"matematica": 6,
"italiano": 7,
"inglese": 5}
materia = "italiano"
voto = votiStud.get(materia)
print("voto di", materia,":", voto)
materia = "ginnastica"
voto = votiStud.get(materia)
print("voto di", materia,":", voto)che produce in output:

Duplicare i dizionari
- Se vogliamo realizzare un duplicato di un dizionario, usiamo il metodo copy() , valido anche per le liste: dizionario.copy()
votiStud = {"studente": "Rossi",
"informatica": 7,
"storia": 8,
"matematica": 6,
"italiano": 7,
"inglese": 5}
copiaVoti = votiStud.copy()
print(votiStud)
print(copiaVoti)Accedere a tutti gli elementi
Se vogliamo accedere a tutti gli elementi di un dizionario, possiamo impostare un ciclo di lettura con la clausola in: il dizionario verrà letto elemento per elemento e la variabile elemento conterrà la chiave:
Copied!for elemento in dizionario: Istruzioni
All’interno della clausola in, possiamo usare i metodi values() e keys() per accedere, rispettivamente, solo ai valori o alle chiavi di un dizionario:
Copied!for valore in dizionario.values(): Istruzioni for chiave in dizionario.keys(): Istruzioni
Applichiamo entrambi i metodi al nostro dizionario:
votiStud = {"studente": "Rossi",
"informatica": 7,
"storia": 8,
"matematica": 6,
"italiano": 7,
"inglese": 5}
print("elenco delle chiavi e dei valori")
for elemento in votiStud:
print(elemento, "-", votiStud[elemento])
print("\nelenco delle chiavi")
for chiave in votiStud.keys():
print(chiave)
print("\nelenco dei valori")
for valore in votiStud.values():
print(valore)
Sottodizionari
Possiamo anche immaginare dizionari con sottodizionari o liste di dizionari; nel primo caso, per esempio se volessimo separare i dati descrittivi dello studente dai suoi voti, potremmo immaginare un dizionario con i voti in una struttura “figlio”:
votiStud = {"cognome": "Rossi",
"nome": "Mario",
"classe": "3Csa",
"voti":{
"informatica": 7,
"storia": 8,
"matematica": 6,
"italiano": 7,
"inglese": 5}
}
print("lo studente", votiStud["cognome"],"ha i seguenti voti")
for elemento in votiStud["voti"]:
print(elemento, "-", votiStud["voti"][elemento])
In questo caso abbiamo un unico studente, ma se ne avessimo più di uno, potremmo organizzare i dati in una specie di tabella, implementando una lista di dizionari
votiStud = []
votiStud.append({"cognome": "Rossi",
"nome": "Mario",
"classe": "3Csa",
"voti":{
"informatica": 7,
"storia": 8,
"matematica": 6,
"italiano": 7,
"inglese": 5}
})
votiStud.append({"cognome": "Bianchi",
"nome": "Elena",
"classe": "3Csa",
"voti":{
"informatica": 6,
"storia": 8,
"matematica": 4,
"italiano": 8,
"inglese": 5}
})
votiStud.append({"cognome": "Verdi",
"nome": "Enrico",
"classe": "3Csa",
"voti":{
"informatica": 8,
"storia": 7,
"matematica": 8,
"italiano": 5,
"inglese": 5}
})
for i in range(len(votiStud)):
print("lo studente", votiStud[i]["cognome"],"ha i seguenti voti")
for elemento in votiStud[i]["voti"]:
print(elemento, "-", votiStud[i]["voti"][elemento])
Lascia un commento