
In questo articolo, “Lavorare con i file in Python” vediamo in che modo sia possibile leggere, scrivere e modificare file testuali utilizzando Python
Introduzione
I file, che siano in input oppure in output, possono avere un’architettura complessa oppure non avere alcuna particolare organizzazione e costituire dei semplici file di testo.
E’ possibile lavorare con i file atteaverso script Python.
In generale, bisogna dichiarare all’inizio in quale modo si vuole utilizzare un file, cioè:
- in input
- in output
- in modifica
La dichiarazione è necessaria perché così il file system del sistema operativo
può decidere se bloccare oppure no il file: in base all’uso che se ne vuole fare, infatti, sarà necessario consentire o impedire ad altre applicazioni di visualizzarne o modificarne il contenuto.
Se un programma richiede il file solo in input (sola lettura), il file può essere letto anche da altre applicazioni, ma non può essere modificato.
Se un programma richiede il file in modifica, allora tale file non può essere utilizzato da nessun’altra applicazione
È molto importante ricordarsi di inserire l’istruzione di chiusura del file nel programma, perché così il sistema operativo può rilasciare il blocco su questa risorsa quando non è più utilizzata, permettendo ad altre applicazioni di usarla.
In ogni caso, alla conclusione del programma il sistema operativo rilascia tutte le risorse impegnate.
Lettura e scrittura su file
La prima istruzione che è necessario fornire per usare un file in un programma è quella di apertura. L’istruzione di apertura serve a:
- reperire il file nel file system del sistema operativo; per trovarlo è sufficiente indicare il nome del file e la relativa estensione se il file è contenuto nella stessa cartella del programma in esecuzione; altrimenti sarà necessario indicarne il percorso;
- dare un nome logico al file che sarà il nome con il quale verrà riconosciuto nel programma;
- stabilire il modo in cui si vuole usare il file (che può essere r per read, w per write, a per inserire i valori in coda al file, r+ per leggere il contenuto del file e aggiungere qualcosa alla fine.
L’istruzione di apertura posiziona il puntatore sul primo byte del file si tratterà poi di organizzare il ciclo di lettura dei dati in modo diverso a seconda di come sono organizzate le informazioni nel file stesso e di come si vuole impostarne l’elaborazione.
Per aprire il file input.txt (nella stessa cartella del programma) in modalità lettura:
Copied!f = open("input.txt", "r")
Nel file possono esserci dei rimandi a capo che ne definiscono le righe; se si vuole leggere il file riga per riga si può impostare un ciclo for di questo tipo:
Copied!for line in f: elaborazione della riga
In questo modo si definisce la variabile line per contenere le righe del file, una riga per volta. Ogni riga contiene anche il carattere speciale per mandare a capo (\n); quindi si utilizza il metodo strip() per eliminare questo carattere se presente:
Copied!for line in f: line = line.strip()
Volendo realizzare il programma per leggere tutto un file, riga per riga, si mette il contenuto di ciascuna riga in una lista (in questo programma visualizziamo la lista nella shell senza formattazioni):
f = open("input.txt", "r")
lista = []
for line in f:
line = line.strip()
lista.append(int(line))
print(lista)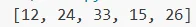
In questo esempio si vede l’uso del metodo strip() per eliminare l’a capo;
il risultato di questa operazione viene trasformato con la funzione int() e poi aggiunto alla lista
Per poter scrivere su un file, il file va aperto in scrittura con il tipo di operazione w, write. Aprendo in modalità scrittura un file esistente si perde il suo contenuto; se il file invece non esiste, allora viene creato con il nome indicato e nel percorso definito.
Copied!foutput = open("output.txt", "w")
Si può scrivere su un file di testo con il metodo write():
Copied!foutput.write(testo)
Tra le parentesi tonde dovrà essere messa una variabile in formato testo, o un testo fisso (fra apici); una particolarità di questo metodo è che non si vedrà quello che abbiamo scritto nel file finché non lo chiudiamo:
Copied!foutput.close()
Ecco il programma per scrivere su un file i primi 10 numeri naturali, uno per riga:
fOutput = open("output.txt", "w")
fOutput.write("elenco numeri naturali da 1 a 10\n")
for i in range(1, 11):
testo = str(i) + "\n"
fOutput.write(testo)
fOutput.close()
Per poter aggiungere del testo su un file, il file va aperto in scrittura con la modalità a, append. Aprendo in modalità append un file inesistente, questo viene creato con
il nome indicato e nel percorso definito.
Copied!f = open("input.txt", "a")
Se invece volessimo sia leggere un file sia aggiungere del contenuto dovremmo usare il tipo di operazione r+ nel comando di apertura del file.
Copied!f = open("input.txt", "r+")
fModifica = open("output.txt", "r+")
fModifica.readline()
somma = 0
conta = 0
for riga in fModifica:
numero = riga.strip()
somma += eval(numero)
conta += 1
somma= "\n" + "somma = " + str(somma)
fModifica.write(somma)
media= "\n" + "media = " + str(somma/conta)
fModifica.write(media)
fModifica.close()Il dato letto da file è per definizione un testo, quindi per trasformarlo in numero si può usare la funzione eval() oppure float() o int(), come in precedenza
All’inizio di questo programma è stato usato il metodo readline() sul file di input, per leggere una riga fuori dal ciclo for.
Si potrebbe usare questo metodo anche all’interno di un ciclo
Per leggere il contenuto di un file e visualizzarlo nella shell, senza fare alcuna
elaborazione, possiamo utilizzare il metodo read():
Copied!contenuto = print(f.read())
Copia e ridenominazione di file e cartelle
Python può facilmente accedere al file system del sistema operativo; quindi, con delle istruzioni di linguaggio si possono cancellare, modificare, spostare i file o le cartelle memorizzate in locale. Le istruzioni necessarie per queste operazioni non sono native del linguaggio, quindi si devono includere le librerie shutil e os che permettono il collegamento al file system. La libreria shutil è di più alto livello rispetto alla os e quindi contiene istruzioni più potenti.
Se vogliamo mostrare in shell il path della cartella nella quale in un dato
momento sta girando il programma, possiamo usare il comando getcwd() della libreria os:
Copied!os.getcwd()
import os
print("percorso della cartella corrente ", os.getcwd())
Cambio di directory
Se vogliamo spostarci in un’altra cartella, di cui conosciamo il percorso, e vedere l’elenco degli elementi presenti:
import os
os.chdir("C:/dir1/dir2" )
print ("adesso la cartella corrente è ", os.getcwd())
print("elenco degli elementi ", os.listdir())Come si vede nella seconda riga del programma, se vogliamo spostarci in una
sottocartella della cartella corrente, dobbiamo usare l’istruzione chdir(path), specificando il percorso come parametro; se scriviamo solo il nome della sottocartella, allora si esprime un path relativo e non assoluto
Con il comando listdir() si richiede la lista degli elementi presenti (senza parametro mostra la lista della cartella corrente) e nella shell verrà visualizzata la lista di tutti gli elementi della cartella, indipendentemente del fatto che si tratti di sottocartelle o file
Lavorare con i file .csv – La libreria PANDAS
I file CSV possono essere aperti come fogli di calcolo (per esempio Excel, Calc ecc.), dando all’applicativo le opportune indicazioni sul separatore che viene usato nel CSV per separare le colonne (in questo caso viene usato il punto e virgola). Il file presenta una certa struttura e per leggerlo in Python si possono usare i comandi della libreria Pandas che non è una libreria disponibile nativamente nell’ambiente di programmazione; bisogna quindi importare le funzioni di libreria con il comando:
Copied!pip install pandas
Qui di seguito è riportato un codice d’esempio per leggere un file CSV con
Pandas:
import pandas as pd
# lettura del CSV con specifica dell'encoding
datiEnergia = pd.read_csv(
'Consumi-energia-elettrica-da-fonti-rinnovabili-escluso-idro-per-regione.csv',
sep=';',
encoding='latin1' # oppure 'cp1252' o 'ISO-8859-1'
)
# ispezione dei dati
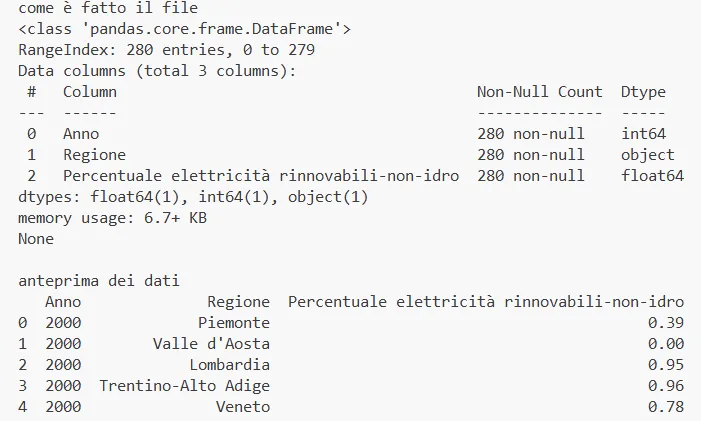
print("come è fatto il file ")
print(datiEnergia.info())
print("\nanteprima dei dati ")
print(datiEnergia.head())Fondamentale specificare la codifica altrimenti il file potrebbe non essere leggibile. Qui di seguito il link al quale si possono scaricare dei file di esempio .csv: http://www.datiopen.it/it/opendata/Consumi_energia_elettrica_da_fonti_rinnovabili_escluso_idro_per_regione?t=Tabella
L’istruzione più importante è read_csv() alla riga 5 che permette di memorizzare il file in un oggetto; in un prossimo articolo si affronterà nei particolari il paradigma di programmazione a oggetti, ma possiamo già vedere come funziona in Pandas, perché si tratta di un sistema piuttosto intuitivo:read.csv(parametri)
Oltre al nome del file che si vuole importare nel programma, è possibile personalizzare il modo in cui vogliamo che il programma ci restituisca la tabella: se, per esempio, la prima riga debba essere occupata dalle intestazioni, il modo in cui vengono separate le colonne e altro.
Una volta che il file è diventato un oggetto, possiamo avvalerci di tutti i metodi
(comandi) disponibili in Pandas; precedentemente, per esempio, sono stati usati info() e head() che ci danno un’idea di come è fatto il DataFrame.
Pandas, infatti, mette a disposizione due diverse strutture di dati: Series, una struttura unidimensionale, paragonabile a un array; DataFrame, una struttura bidimensionale, paragonabile a un foglio di calcolo dove ogni cella può contenere un valore.
Con il metodo loc[indice] possiamo reperire una riga; l’indice fa riferimento al numero della riga del foglio di calcolo dove risiedono i dati presi in considerazione:
import pandas as pd
# lettura del CSV con specifica dell'encoding
datiEnergia = pd.read_csv(
'Consumi-energia-elettrica-da-fonti-rinnovabili-escluso-idro-per-regione.csv',
sep=';',
encoding='latin1' # oppure 'cp1252' o 'ISO-8859-1'
)
# ispezione dei dati
print("dati della riga di indice 2 ")
print(datiEnergia.loc[2])
miaSerie1 = datiEnergia.Regione
miaSerie2 = datiEnergia['Regione']
Piemonte = datiEnergia[ datiEnergia['Regione'] == 'Lombardia' ]
percEnegRinnovabile = Piemonte['Percentuale elettricità rinnovabili-non-idro']
print("\nStatistiche sul Piemonte ")
print(percEnegRinnovabile.describe())
L’oggetto miaSerie1 contiene la serie della colonna dei nomi delle regioni.
Con la riga di codice:
Piemonte = datiEnergia[ datiEnergia[‘Regione’] == ‘Lombardia’ ]
viene creato un nuovo DataFrame, che chiamiamo Lombardia, selezionando i dati che hanno Regione = ‘Lombardia’.
Con il metodo describe() si calcolano automaticamente una serie di indici statistici
Lascia un commento