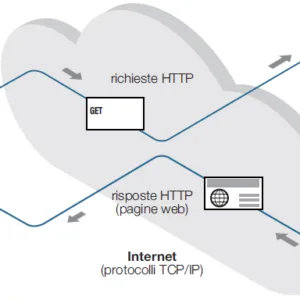
La comunicazione sul Web avviene attraverso protocolli di rete che operano al livello applicazione, utilizzando il protocollo di trasporto TCP. Tra questi, il più diffuso è il protocollo HTTP (HyperText Transfer Protocol), che segue un modello di cooperazione asimmetrica tra due entità fondamentali: client e server. Questi due elementi hanno ruoli ben distinti all’interno del sistema di comunicazione.
Indice dei contenuti
- Il modello Client–Server e la comunicazione sul Web
-
Il protocollo HTTP
- Come avviene una comunicazione HTTP
- Connessioni HTTP e versioni del protocollo
- Struttura dei messaggi HTTP
- Gli Header HTTP
- Metodi HTTP principali
- Passaggio di parametri con il metodo GET
- Passaggio di parametri con il metodo POST
- Passaggio di parametri con il metodo PUT
- Passaggio di parametri con il metodo DELETE
- Codici di stato HTTP
- La codifica URL
- Analisi del traffico HTTP
Il modello Client–Server e la comunicazione sul Web
Alla base del funzionamento del Web troviamo il modello client–server, un’architettura in cui due entità svolgono ruoli ben distinti: il client richiede un servizio, il server lo fornisce. Questa separazione dei compiti consente di realizzare sistemi scalabili, affidabili e facilmente manutenibili.
Il ruolo del client nella comunicazione
Il client rappresenta il punto di partenza della comunicazione. È il soggetto attivo che prende l’iniziativa, avviando una richiesta verso un server remoto. Nel contesto del Web, il client è tipicamente un browser (come Chrome o Firefox) oppure un’applicazione che utilizza il protocollo HTTP per accedere a risorse online.
Quando un utente digita un indirizzo web o clicca su un collegamento, il client costruisce una richiesta HTTP specificando l’URL della risorsa desiderata, l’indirizzo del server e la porta del servizio, generalmente la porta 80 per HTTP o la 443 per HTTPS. Dopo l’invio della richiesta, il client rimane in attesa della risposta, che può contenere una pagina HTML, un file multimediale o dati strutturati come JSON o XML.
Un esempio tipico di richiesta HTTP inviata da un client è il seguente:
Copied!GET /index.html HTTP/1.1
Host: www.esempio.com
User-Agent: Mozilla/5.0
Il ruolo del server
Il server svolge un ruolo complementare e passivo. Rimane costantemente in ascolto su una specifica porta TCP, pronto a ricevere richieste dai client. Software come Apache, Nginx o IIS gestiscono questo compito, analizzando le richieste ricevute e fornendo le risposte appropriate.
Una volta elaborata la richiesta, il server restituisce un messaggio di risposta HTTP, che può contenere la risorsa richiesta oppure un codice di errore, come il noto 404 Not Found. Un esempio di risposta corretta è il seguente:
Copied!HTTP/1.1 200 OK Content-Type: text/html Content-Length: 1024
Il corpo del messaggio conterrà poi il contenuto effettivo, come una pagina HTML.
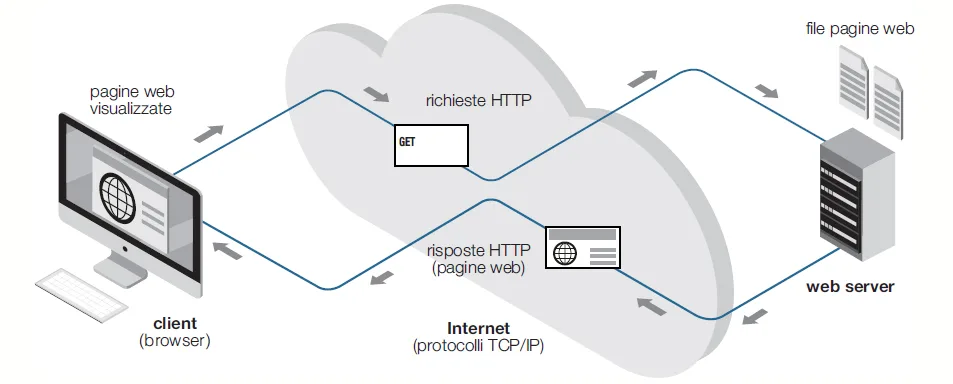
Il protocollo HTTP
Il protocollo HTTP (HyperText Transfer Protocol) è il fondamento della comunicazione sul Web. È un protocollo di livello applicativo che permette lo scambio di risorse tra client e server sfruttando il protocollo TCP come mezzo di trasporto.
Il Web nasce dalla combinazione di tre elementi fondamentali:
HTML per la struttura delle pagine, URL per l’indirizzamento delle risorse e HTTP per la comunicazione vera e propria.
Come avviene una comunicazione HTTP
Una comunicazione HTTP inizia sempre con l’apertura di una connessione TCP, solitamente sulla porta 80. Il client invia una richiesta, il server elabora la richiesta e invia una risposta. Nella forma più semplice, la connessione viene chiusa subito dopo l’invio della risposta.
Accedendo, ad esempio, a una pagina web, il browser richiede il file HTML principale. Una volta ricevuto, analizza il contenuto e, se individua immagini o altri elementi, avvia nuove richieste HTTP per ciascuna risorsa necessaria.
Connessioni HTTP e versioni del protocollo
Con HTTP/1.1 è stato introdotto il concetto di connessione persistente, che consente di riutilizzare la stessa connessione TCP per più richieste consecutive. Questo meccanismo migliora sensibilmente le prestazioni, riducendo il numero di connessioni da aprire e chiudere.
Le richieste possono essere inviate una alla volta oppure in modalità pipelined, cioè in sequenza senza attendere le risposte precedenti.
Struttura dei messaggi HTTP
I messaggi HTTP, sia di richiesta che di risposta, seguono una struttura ben definita composta da una riga iniziale, un insieme di intestazioni e, opzionalmente, un corpo del messaggio.
Nel caso di una richiesta HTTP, la riga iniziale indica il metodo utilizzato, la risorsa richiesta e la versione del protocollo:
Copied!GET /percorso/file.html HTTP/1.1
Le intestazioni forniscono informazioni aggiuntive, come il tipo di contenuto accettato o il browser utilizzato. Il corpo del messaggio, invece, è presente solo in alcuni metodi, come POST o PUT, ed è utilizzato per trasmettere dati al server.
Esempio di richiesta HTTP completa
Copied!GET / HTTP/1.1 Accept: image/gif, image/jpeg, image/png, */* Accept-Language: it Accept-Encoding: gzip, deflate Host: www.magistricumacini.it If-Modified-Since: Fri, 14 Mar 2018 10:54:03 GMT User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0)
La risposta HTTP è organizzata in modo simile a una richiesta HTTP, ma con una differenza fondamentale: la risposta inizia con una riga di stato.
Esempio di una Response HTTP
Copied!HTTP/1.1 200 OK Transfer-Encoding: chunked Date: Sat, 28 Nov 2021, 04:33:04 GMT Server: Apache/1.4 Connection: close Expires: Sat, 28 Nov 2021, 05:33:04 GMT Cache-Control: max-age=3600, public Content-Type: text/html
Nel corpo della risposta (body), troviamo il contenuto richiesto, ad esempio una pagina HTML:
Copied!<HTML> <HEAD> <TITLE>Il protocollo HTTP</TITLE> </HEAD> <BODY> <h1>Benvenuti alla lezione sul protocollo HTTP!</h1> <p>Questo è un esempio di risposta HTTP con un corpo HTML.</p> </BODY> </HTML>
Gli Header HTTP
Gli header della risposta, come quelli della richiesta, sono formati da coppie nome: valore che descrivono le caratteristiche del messaggio. Questi header possono riguardare informazioni generali sulla trasmissione, come il tipo di compressione (es. Transfer-Encoding), Caratteristiche dell’entità trasmessa, come il tipo di contenuto (es. Content-Type) o la data di scadenza della risorsa (es. Expires), dettagli relativi alla richiesta, come il User-Agent (che indica il browser utilizzato) o l’host richiesto, dettagli sulla risposta generata dal server, come il tipo di server (es. Server) o le modalità di autenticazione richieste (es. WWW-Authenticate).
I principali metodi HTTP
I metodi HTTP esprimono l’azione che il client intende compiere sulla risorsa:
-
GET consente di richiedere una risorsa. Una richiesta GET è di sola lettura, ma quando il client riceve le informazioni, è libero di compiere operazioni sui dati ricevuti, come per esempio formattarle per visualizzarle. Esempio:
GET /pathname HTTP/1.1 -
POST permette di inviare dati al server. I dettagli di identificazione e di elaborazione della risorsa non sono indicati nell’URL, ma sono collocati nel body del messaggio. Esempio:
POST /pathname HTTP/1.1 - PUT viene utilizzato per creare o aggiornare una risorsa. Se è stata creata una nuova risorsa, il server deve informare l’user agent (browser Web) con una risposta 201 Created. Se invece viene modificata una risorsa già esistente, dovrebbero essere mandati i codici di risposta 200 OK oppure 204 No Content a indicare il successo della richiesta. Esempio: PUT /pathname/1 HTTP/1.1
- DELETE richiede l’eliminazione di una risorsa. Un server può rispondere positivamente alla richiesta con metodo DELETE con 200 OK (la risorsa è stata eliminata), 202 Accepted (l’azione non è stata ancora effettuata) oppure 204 No Content (l’azione è stata effettuata ma la risposta non include un’entità)
Questi metodi sono alla base delle applicazioni web moderne e delle architetture RESTful.
Passaggio di parametri con il metodo GET
Il metodo GET viene utilizzato per richiedere una risorsa al server. I parametri vengono inseriti direttamente nell’URL, sotto forma di query string.
Esempio pratico
Un utente effettua una ricerca di un prodotto su un sito web.
URL digitato nel browser:
Copied!https://www.esempio.it/cerca?categoria=libri&autore=rossi
In questo caso:
-
categoria=libriè un parametro -
autore=rossiè un secondo parametro - i parametri sono separati dal simbolo
&
Richiesta HTTP generata
Copied!GET /cerca?categoria=libri&autore=rossi HTTP/1.1 Host: www.esempio.it
Il server riceve i parametri dalla URL e li utilizza, ad esempio, per interrogare un database e restituire i risultati della ricerca.
📌 Nota: i parametri GET sono visibili nella barra degli indirizzi e quindi non adatti a dati sensibili.
Passaggio di parametri con il metodo POST
Il metodo POST viene usato per inviare dati al server, tipicamente tramite form HTML. I parametri non sono visibili nell’URL, ma vengono inseriti nel corpo del messaggio HTTP.
Esempio pratico: invio di un form di login
Un utente inserisce username e password in una pagina di accesso.
Richiesta HTTP POST
Copied!POST /login HTTP/1.1 Host: www.esempio.it Content-Type: application/x-www-form-urlencoded Content-Length: 39 username=mario.rossi&password=segretissima
In questo caso:
- i parametri sono contenuti nel body
- il server riceve i dati e li elabora (ad esempio verificando le credenziali)
📌 Nota: POST è più sicuro di GET, ma non cifra i dati (la sicurezza reale è garantita da HTTPS).
Passaggio di parametri con il metodo PUT
Il metodo PUT viene utilizzato per creare o aggiornare una risorsa specifica sul server. I parametri sono generalmente inclusi nel corpo del messaggio.
Esempio pratico: aggiornamento di un profilo utente
Si vuole aggiornare i dati dell’utente con ID 15.
Richiesta HTTP PUT
Copied!PUT /utenti/15 HTTP/1.1 Host: api.esempio.it Content-Type: application/json { "email": "mario.rossi@email.it", "telefono": "3331234567" }
In questo scenario:
- l’URI identifica la risorsa (
/utenti/15) - i parametri sono nel corpo in formato JSON
- il server aggiorna la risorsa esistente
📌 PUT è idempotente: ripetere la stessa richiesta produce sempre lo stesso risultato.
Passaggio di parametri con il metodo DELETE
Il metodo DELETE richiede al server la rimozione di una risorsa. Di norma il parametro principale è incluso direttamente nell’URI.
Esempio pratico: eliminazione di un ordine
Copied!DELETE /ordini/102 HTTP/1.1 Host: api.esempio.it
In questo caso:
-
102identifica l’ordine da eliminare - non è necessario un corpo del messaggio
- il server risponde indicando l’esito dell’operazione
Riepilogo concettuale
- GET → parametri nella URL (query string)
- POST → parametri nel corpo del messaggio
- PUT → parametri nel corpo per creare/aggiornare risorse
- DELETE → parametro principale nell’URI
Codici di stato HTTP
Ogni risposta HTTP contiene un codice di stato che indica l’esito della richiesta. I codici più comuni rientrano nelle classi 2xx per il successo, 4xx per gli errori del client e 5xx per gli errori del server. Questo meccanismo consente al client di interpretare correttamente il risultato della comunicazione. Vediamo alcuni esempi:
Esempio 1: Codice di stato 200 OK
Il codice 200 OK indica che la richiesta inviata dal client è stata elaborata correttamente dal server e che la risorsa richiesta è stata restituita senza errori.
Situazione tipica
Un utente digita l’indirizzo di una pagina web nel browser e il server risponde fornendo correttamente il contenuto richiesto.
Esempio di risposta HTTP:
Copied!HTTP/1.1 200 OK Content-Type: text/html Content-Length: 1250
In questo caso il server comunica al client che l’operazione ha avuto successo e che nel corpo della risposta è presente la pagina HTML richiesta.
Esempio 2: Codice di stato 404 Not Found
Il codice 404 Not Found indica che il server è stato raggiunto correttamente, ma la risorsa richiesta non esiste o non è disponibile all’indirizzo specificato.
Situazione tipica
Un utente tenta di accedere a una pagina eliminata o scrive un URL in modo errato.
Esempio di risposta HTTP:
Copied!HTTP/1.1 404 Not Found Content-Type: text/html
In questo caso il server informa il client che la richiesta è valida, ma la risorsa non è stata trovata.

La codifica URL
La codifica URL (URL encoding) è il meccanismo che consente di trasformare una stringa di testo in un formato compatibile con la trasmissione tramite richieste HTTP. Questo processo è fondamentale quando si inviano dati al server attraverso i metodi GET e POST, in particolare nel caso dei moduli HTML e delle query string.
Durante una comunicazione HTTP, infatti, non tutti i caratteri possono essere inseriti direttamente all’interno di un URL. Alcuni simboli hanno un significato speciale per il protocollo oppure potrebbero causare ambiguità nell’interpretazione della richiesta. Per questo motivo, tali caratteri devono essere convertiti in una forma standardizzata.
Ad esempio, la stringa:
Copied!societa=Rossi & Martini
dopo la codifica URL diventa:
Copied!societa=Rossi%26Martini
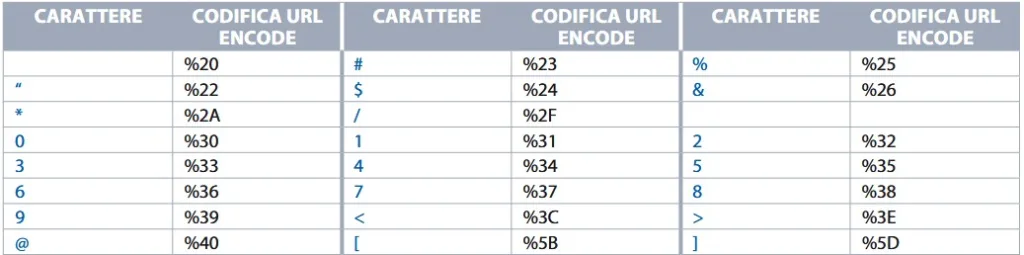
In questo caso, il carattere &, che in un URL viene utilizzato come separatore tra parametri, viene sostituito dalla sequenza %26, che rappresenta il suo valore ASCII in formato esadecimale. Lo stesso principio si applica ad altri caratteri speciali, come %, @, + e agli spazi.
La codifica URL viene utilizzata principalmente nelle QueryString, ovvero nella parte dell’URL che contiene i parametri trasmessi dal client al server. Tuttavia, essa non è limitata ai moduli HTML (tag <form>), ma viene applicata anche alle richieste generate tramite collegamenti ipertestuali (tag <a href>), garantendo che i dati inclusi nell’URL siano sempre conformi agli standard del protocollo.
In generale, una stringa da codificare è composta da una serie di coppie nome–valore. Il processo di codifica prevede alcuni passaggi fondamentali. I caratteri non sicuri vengono sostituiti da una sequenza formata dal simbolo % seguito dal codice ASCII del carattere espresso in esadecimale. Gli spazi, che non possono comparire direttamente in un URL, vengono convertiti nella sequenza %20. Infine, i nomi dei parametri vengono associati ai rispettivi valori tramite il simbolo =, mentre le diverse coppie vengono separate dal carattere &.
Questo meccanismo assicura che le informazioni trasmesse dal client al server siano interpretate correttamente, evitando errori di parsing e problemi di compatibilità tra browser, server e applicazioni web.:
Analisi del traffico HTTP
Per osservare e comprendere il funzionamento di HTTP in modo pratico, strumenti come Chrome Developer Tools e cURL risultano fondamentali. Essi permettono di analizzare in tempo reale le richieste, le risposte e gli header scambiati tra client e server.
Lascia un commento