
In questo articolo studiamo Il Processore Intel 8086 le sue componenti ed il funzionamento
Esercizi svolti Assembly 8086 (240 download )Sommario
- Introduzione
- Dal linguaggio umano al codice macchina
- Programma e Algoritmo: differenze
- Classificazione dei linguaggi di programmazione
- Architettura del Processore 8086
Introduzione
Un elaboratore, per quanto potente, non è in grado di svolgere alcuna funzione senza un programma che lo istruisca sui compiti da eseguire. Accanto all’hardware, è quindi necessario il software, l’insieme dei programmi che permettono il funzionamento del sistema.
La collaborazione tra hardware e software è alla base del successo di ogni applicazione informatica. Per comprendere come funzionano i programmi, è utile conoscere il linguaggio che l’elaboratore comprende realmente: il codice macchina, in cui ogni istruzione è codificata come una sequenza di bit (0 e 1) che indica le operazioni da eseguire e gli operandi su cui agire.
Dal linguaggio umano al codice macchina
Nel corso del tempo sono nati numerosi linguaggi di programmazione che fungono da ponte tra il linguaggio umano e il linguaggio binario della macchina. Tuttavia, qualsiasi linguaggio di programmazione, per poter essere eseguito dalla CPU, deve essere tradotto in codice macchina, attraverso un processo di compilazione o interpretazione.
Un programma, una volta scritto, deve essere salvato su un file, ma per essere effettivamente eseguito dal computer, deve essere tradotto in codice binario e caricato in memoria. Questo processo di traduzione e caricamento in memoria viene gestito dai software di base, che includono strumenti come compilatori, assemblatori e linker.
Fasi di Traduzione e Esecuzione di un Programma
- Codice Sorgente: Il programma viene inizialmente scritto in un linguaggio di programmazione comprensibile dall’uomo (ad esempio, C, C++, Java). Questo codice viene salvato in un file sorgente.
- Compilazione/Assemblaggio: Un compilatore (per linguaggi come C o C++) o un assemblatore (per linguaggi a basso livello come l’Assembly) analizza il codice sorgente, effettua un’analisi sintattica e lo traduce in codice binario. Questo processo genera il file oggetto, che contiene il programma in una forma che il computer può comprendere, ma non è ancora eseguibile.
- Linking: Un linker prende uno o più file oggetto e li combina in un unico file eseguibile. Il linker si occupa anche di risolvere le eventuali dipendenze tra i vari moduli del programma, come librerie esterne, creando così il file eseguibile finale. Questo file eseguibile è quindi pronto per essere caricato in memoria e eseguito dal processore.

Linguaggi Compilati e Interpretati
Alcuni linguaggi di programmazione utilizzano sia compilatori che interpreti, mentre altri si basano esclusivamente su uno dei due strumenti.
- Compilati: Linguaggi come C e C++ utilizzano un compilatore per tradurre il codice sorgente direttamente in codice macchina, che può essere eseguito dalla CPU. Una volta compilato, il programma non ha più bisogno del codice sorgente per essere eseguito.
- Interpretati: Linguaggi come JavaScript sono eseguiti da un interprete che traduce il codice sorgente linea per linea durante l’esecuzione. In questo caso, il programma non viene mai tradotto in un file binario pre-compilato, ma viene interpretato direttamente al momento dell’esecuzione.
- Compilazione Intermedia: Java adotta un approccio misto. Il codice sorgente viene prima tradotto in un bytecode (un linguaggio intermedio), che non è eseguibile direttamente dalla macchina, ma viene successivamente interpretato dalla Java Virtual Machine (JVM). In questo modo, il programma è portabile su diverse piattaforme, poiché la JVM si occupa di eseguire il bytecode su qualsiasi sistema.
Programma e Algoritmo: differenze
È importante distinguere il concetto di algoritmo da quello di programma:
- Algoritmo: è una sequenza finita di istruzioni, scritta in linguaggio naturale (pseudocodice), volta a risolvere un problema.
- Programma: è l’algoritmo tradotto in un linguaggio di programmazione, affinché possa essere compreso ed eseguito dalla CPU.
Un algoritmo può essere scritto anche su carta; un programma, invece, deve essere salvato in un file sorgente, pronto per essere elaborato dal compilatore o dall’interprete.
Per uno stesso problema possono esistere più algoritmi, e ciascuno può essere implementato con diversi linguaggi di programmazione. La scelta del linguaggio dipende dal contesto, dalla piattaforma di destinazione e dalle preferenze del programmatore.
Classificazione dei linguaggi di programmazione
I linguaggi di programmazione si suddividono generalmente in due grandi categorie:
Linguaggi di alto livello
Esempi: C, C++, Java, Python, Pascal
- Più vicini al linguaggio umano e allo pseudocodice.
- Più facili da leggere e comprendere.
- Utilizzano strutture di controllo (condizioni, cicli, funzioni, ecc.).
- Sono indipendenti dall’hardware.
- Richiedono un compilatore o un interprete per essere eseguiti.
In questi linguaggi si utilizzano le variabili, che rappresentano un’astrazione delle celle di memoria. Il programmatore lavora con nomi simbolici, senza conoscere gli indirizzi fisici, grazie al lavoro del compilatore che si occupa dell’associazione tra nome e locazione di memoria.
Linguaggi di basso livello
Esempio: Assembly
- Più vicini all’architettura hardware del calcolatore.
- Più difficili da comprendere per l’uomo.
- Non utilizzano strutture di controllo complesse.
- Sono dipendenti dall’hardware: ogni CPU ha il proprio set di istruzioni.
Il linguaggio macchina e l’Assembly
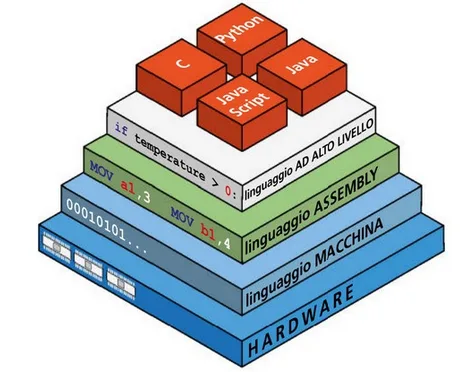
Il linguaggio macchina rappresenta il livello più basso: ogni istruzione è composta da una sequenza di bit (0/1). A questo livello, il programma è direttamente eseguibile dall’hardware, ma risulta incomprensibile per un essere umano.
Un gradino più in alto troviamo il linguaggio Assembly, che utilizza codici mnemonici (ad esempio MOV, ADD, SUB) per rendere il codice più leggibile. Tuttavia, ogni istruzione in Assembly corrisponde direttamente a un’istruzione in codice macchina.
Ogni architettura hardware ha un proprio linguaggio Assembly. Per eseguire un programma scritto in Assembly è necessario un assemblatore (Assembler), che si occupa della traduzione in codice macchina.
Nel linguaggio Assembly, ogni locazione di memoria è identificata tramite un indirizzo. Il programmatore deve gestire direttamente questi indirizzi e controllare l’esecuzione a basso livello.
Architettura del Processore 8086
Il microprocessore 8086 rappresenta l’architettura di base della famiglia x86, progettata da Intel. Questo processore ha un’architettura CISC (Complex Instruction Set Computing) e un ISA (Instruction Set Architecture) che è compatibile con i modelli successivi della famiglia, portando alla diffusione di questa architettura nei Personal Computer (PC) desktop e laptop.
Le principali caratteristiche dell’architettura del 8086 sono le seguenti:
- Bus Dati a 16 bit: Il processore è in grado di trasferire 2 byte alla volta in un’unica operazione, grazie alla larghezza del bus dati di 16 bit.
- Bus Indirizzi a 20 bit: Con questo bus, l’8086 è capace di indirizzare 1 megabyte (MB) di memoria, cioè 2^20 locazioni di memoria, che corrispondono a un indirizzo di memoria massimo di 1.048.576 byte.
- 14 Registri a 16 bit: Il processore è dotato di 14 registri di 16 bit che svolgono un ruolo fondamentale nelle operazioni di elaborazione e gestione dei dati.
Unità di Esecuzione (EU) e Unità di Interfaccia al Bus (BIU)
La CPU 8086 è composta da due unità principali che svolgono funzioni distinte ma complementari:
- Execution Unit (EU): È responsabile dell’esecuzione delle istruzioni. La EU si occupa della logica e del controllo delle operazioni aritmetiche e logiche, ed è il cuore della parte di calcolo del processore.
- Bus Interface Unit (BIU): Si occupa della gestione della comunicazione con il bus, cioè dell’accesso alla memoria e ai dispositivi di I/O. È incaricata di prelevare le istruzioni dalla memoria e di trasferire i dati tra la CPU e il sistema di memoria.
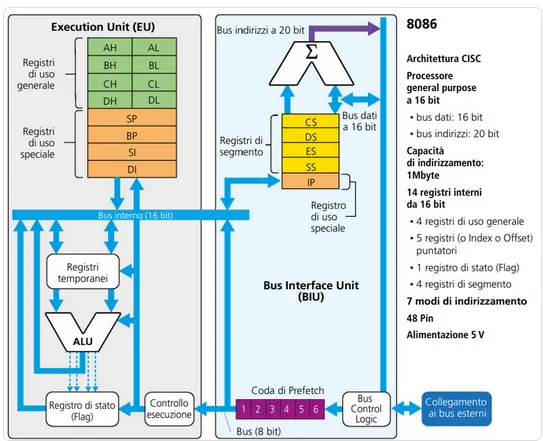
Lavoro Parallelo delle Due Unità
Una delle caratteristiche più avanzate del 8086 è la capacità di eseguire operazioni in parallelo tra la EU e la BIU. Le due unità possono operare indipendentemente l’una dall’altra. Mentre la EU esegue un’istruzione (fase di esecuzione), la BIU può iniziare a prelevare dalla memoria l’istruzione successiva.
Questo tipo di concorrenza è reso possibile dalla prefetch queue, una coda di prefetch gestita secondo una politica FIFO (First In First Out), che consente alla BIU di immagazzinare le istruzioni da eseguire nella coda. La EU, successivamente, preleva e esegue le istruzioni dalla coda di prefetch.
Pipeline: Il Primo Esempio di Parallelismo
Questa capacità di far lavorare le due unità in parallelo è il primo esempio di pipeline nella storia dei microprocessori. Con il pipeline, il processore non deve aspettare che un’istruzione sia completamente eseguita prima di iniziare a recuperare la successiva. In altre parole, fetch e execute avvengono in modo sovrapposto, migliorando l’efficienza e riducendo i tempi di attesa.
I registri dell’8086
I registri dell’8086 si dividono in:
- Registri GENERAL PURPOSE (ad uso generale)

- Registri SPECIAL PURPOSE (indice e puntatore, contengono indirizzi)

- Registri SEGMENT (usati per la segmentazione della memoria)

- STATUS Register (definisce lo stato della CPU)

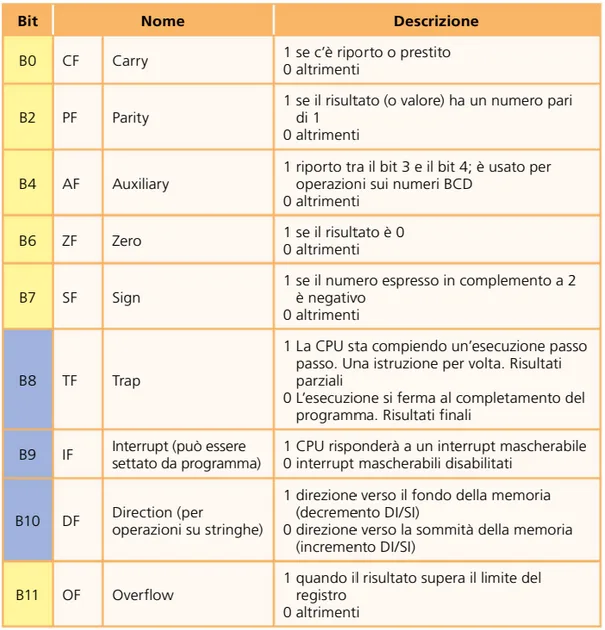
Qui in basso la struttura dello Status Register ed il significato dei flagg:


Organizzazione della Memoria
Segmentazione della Memoria
Il microprocessore 8086 gestisce la memoria attraverso un sistema di segmentazione, in cui la memoria è divisa in blocchi chiamati segmenti. Gli indirizzi di memoria sono di 20 bit, ma i registri utilizzati per l’indirizzamento, come l’Instruction Pointer (IP), sono di 16 bit. Questo pone un problema: come possono i registri a 16 bit contenere un indirizzo a 20 bit? La soluzione risiede nel modo in cui l’8086 gestisce la memoria segmentata.
La memoria è divisa in segmenti che sono porzioni di memoria destinate a specifiche funzioni, come l’archiviazione dei dati o delle istruzioni. Ogni segmento può contenere al massimo 64 kilobyte (kB) di dati, ovvero 2^16 locazioni (indicate da indirizzi che vanno da 0000h a FFFFh), e può essere indirizzato tramite un registro a 16 bit. Per indirizzare una locazione di memoria, l’8086 utilizza un meccanismo che prevede l’uso di due componenti:
- Base: è l’indirizzo di partenza del segmento.
- Spiazzamento (Offset): è l’indirizzo della locazione all’interno del segmento, calcolato a partire dalla base.
L’indirizzo logico della memoria, quindi, è rappresentato dalla coppia base:spiazzamento.
Calcolo dell’Indirizzo Fisico
Dato un indirizzo logico di tipo base:spiazzamento, il microprocessore 8086 calcola l’indirizzo fisico associato come segue:
- Moltiplica la base per 10h (16 decimale). In pratica, si aggiunge uno 0 alla fine della base, ottenendo un indirizzo a 20 bit.
- Somma lo spiazzamento a questo valore ottenuto.
Questa trasformazione viene eseguita automaticamente dalla CPU, che preleva l’indirizzo logico dal programma, lo converte in indirizzo fisico e lo invia sul bus degli indirizzi per accedere alla memoria.

Tipi di Segmento

La memoria dell’8086 è divisa in quattro tipi di segmenti principali. I segmenti possono essere associati a diverse aree della memoria:
- CS (Code Segment): Contiene il codice eseguibile del programma.
- DS (Data Segment): Contiene le variabili e i dati utilizzati dal programma.
- ES (Extra Segment): Spazio opzionale per altri dati, spesso utilizzato per operazioni di stringhe o buffer.
- SS (Stack Segment): Contiene lo stack, utilizzato per gestire le chiamate di funzione e la memoria temporanea.
Ogni segmento ha un registro di segmento (come CS, DS, ES, SS) che contiene la base dell’indirizzo. Lo spiazzamento all’interno di ciascun segmento viene indicato come una parte dell’indirizzo logico.
Ad esempio, un indirizzo logico come B200:23F1 significa che la base del segmento è B200h e lo spiazzamento all’interno di quel segmento è 23F1h. Il programma calcola l’indirizzo fisico aggiungendo il valore dello spiazzamento alla base moltiplicata per 10h.
Inoltre, l’inizializzazione dei registri di segmento che contengono i dati, come DS e ES, è a carico del programmatore. Non è consentito l’uso di indirizzamento immediato, ad esempio non è possibile scrivere direttamente MOV DS, valore. Il valore di base deve essere caricato tramite un altro registro, come AX.

Rilocazione Dinamica dei Programmi
La segmentazione della memoria consente di rendere i programmi rilocabili dinamicamente. Ciò significa che il programma non è legato a una posizione fissa in memoria, ma può essere caricato in qualsiasi spazio di memoria disponibile. In un sistema in multiprogrammazione, i programmi possono essere caricati in spazi di memoria diversi a seconda delle necessità del sistema operativo.
Ad esempio, un programma composto da N istruzioni:
istruzione 1
istruzione 2
istruzione 3
...
istruzione N
Può essere caricato in memoria a partire da un indirizzo qualsiasi, modificando solo la base dell’indirizzo relativo, mentre lo spiazzamento rimane invariato. Questo permette di caricare programmi in posizioni di memoria differenti senza modificare il codice sorgente, se non per la base dell’indirizzo.
I Pin della CPU 8086
Il microprocessore 8086 è dotato di 40 pin che gestiscono le comunicazioni esterne. I pin principali sono:
- 20 linee del bus indirizzi (A0, …, A19): Utilizzate per indirizzare la memoria e i dispositivi.
- 16 linee del bus dati (AD0, …, AD15): Il bus dati, che è condiviso con il bus indirizzi, consente il trasferimento dei dati tra la CPU e la memoria o i dispositivi di I/O.
-
Pin di controllo:
- M/IO (Memory/Input-Output): Differenzia tra operazioni di memoria e operazioni di I/O.
- RD (Read) e WR (Write): Indicano se la CPU sta leggendo o scrivendo dalla memoria o da un dispositivo di I/O.
- INTA (Interrupt Acknowledge): Segnale di riconoscimento degli interrupt mascherabili.
- INTR (Interrupt Request): Richiesta di interrupt mascherabile.
- NMI (Non-Maskable Interrupt): Interruzione non mascherabile.
- BHE (Bus High Enable): Abilita il trasferimento di dati a 8 o 16 bit.
- CLK (Clock): Il segnale di clock per la temporizzazione delle operazioni.
Questi segnali esterni permettono di coordinare il funzionamento della CPU con il resto del sistema, gestendo la comunicazione con la memoria, i dispositivi di input/output e le operazioni di interrupt.

Nella sezione DOWNLOAD oppure direttamente qui: https://profgiagnotti.it/download/7396/?tmstv=1744538174 è possibile scaricare i file .asm relativi agli esercizi svolti
Lascia un commento