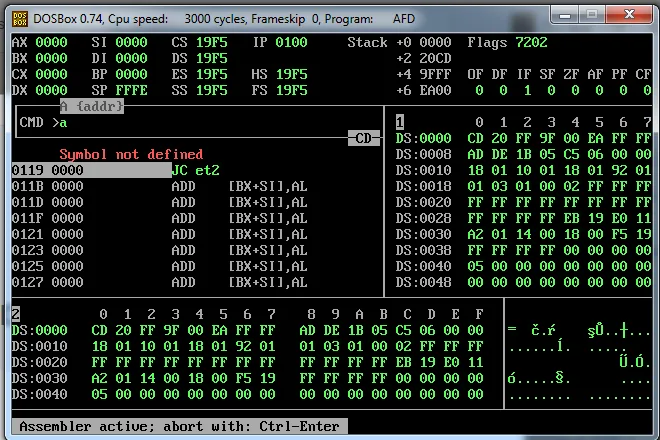
In questa guida “IL LINGUAGGIO ASSEMBLY INTEL X86” parliamo dell’ ISA dell’ 8086 e impariamo alcuni comandi base
Esercizi svolti Assembly 8086 (241 download )Indice dei contenuti
- Generalità
-
Metodi di indirizzamento
- Indirizzamento immediato
- Indirizzamento diretto da registro a registro
- Indirizzamento diretto da registro a memoria e viceversa
- Indirizzamento indiretto tramite registro
- Indirizzamento indiretto tramite registro e displacement
- Indirizzamento indiretto tramite registri base e indice
- Indirizzamento indiretto tramite registri base e indice e con displacement
- L’ISA (Instruction Set Architecture dell’ 8086
- Ambiente di simulazione EMU8086
Generalità
Il codice macchina può essere visto in una forma equivalente attraverso un linguaggio mnemonico, dunque comprensibile all’uomo, al contrario delle sequenze di bit che sono comprensibili solo al microprocessore

Un’istruzione assembly di un generico processore Intel x86 è formata da:
- un’etichetta opzionale (label), che assegna un nome simbolico all’indirizzo di memoria in cui si troverà l’istruzione;
- un codice operativo (opcode) mnemonico obbligatorio, che specifica l’operazione da svolgere;
- zero, uno, due o tre operandi separati da una virgola, che specificano i dati su cui operare; esistono operandi sorgente (anche più di uno), operando destinazione e operando implicito.

Metodi di indirizzamento
I metodi di indirizzamento si suddividono in tre tipi, in base al modo in cui l’istruzione tratta il dato da elaborare:
- immediato: nell’istruzione c’è il dato;
- diretto: nell’istruzione c’è’ l’indirizzo di memoria o il registro in cui si trova il dato;
- indiretto: nell’istruzione c’è’ l’indirizzo di memoria o il registro dove si trova l’indirizzo di memoria in cui c’è’ il dato. In questo tipo di indirizzamento il dato finale può essere solo in memoria e non in un registro o nell’istruzione.

Indirizzamento immediato
Il dato da scrivere è direttamente specificato nel secondo operando dell’istruzione:
MOV AL,4Dh
L’esecuzione di questa istruzione determina, in un unico passo, la scrittura del valore ‘4D’, espresso in esadecimale (h), in AL, ovvero nella parte bassa del registro Accumulator AX.

Indirizzamento diretto da registro a registro
Entrambi gli operandi sono registri, rispettivamente destination e source:
MOV AX,BX
L’esecuzione di questa istruzione provoca, in un unico passo, la copia del contenuto del registro base BX nel registro accumulatore AX

Indirizzamento diretto da registro a memoria e viceversa
Un operando è un registro, mentre l’altro è una locazione di memoria centrale specificata direttamente dall’istruzione mediante l’offset (tra parentesi quadre):
MOV AX,[6Ah]
L’esecuzione di questa istruzione determina prima il calcolo dell’indirizzo in cui si trova il dato realmente, mediante l’operazione:
base address + offset = effective address
Il secondo passo è la copia del valore che si trova in memoria (all’offset “6A”) nel registro AX. Invertendo gli operandi e cioè scrivendo l’istruzione MOV [6Ah],AX, il contenuto di AX verrebbe copiato in memoria all’offset “6A”

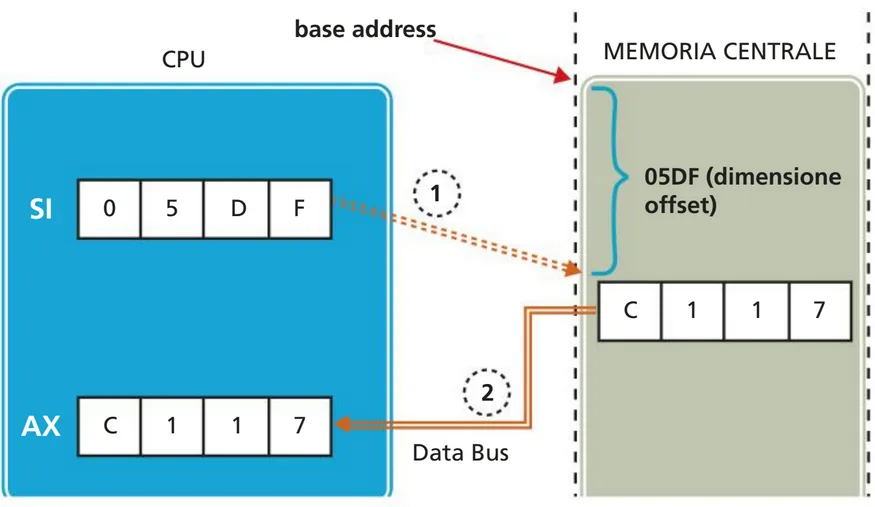
Indirizzamento indiretto tramite registro
Quando nell’architettura della CPU sono previsti anche registri puntatore o indice (per esempio Source Index, SI, per l’operando source e Destination Index, DI, per l’operando destination), è possibile indirizzare tramite registro:
MOV AX,[SI]
L’esecuzione di questa istruzione provoca prima il calcolo dell’indirizzo in cui si trova il dato realmente mediante l’operazione:
base address + source index = effective address
dove però l’offset non è specificato nell’istruzione come nella modalità precedente, ma è in SI. Il secondo passo è la copiatura del valore che si trova in memoria (all’offset contenuto in SI) nel registro AX
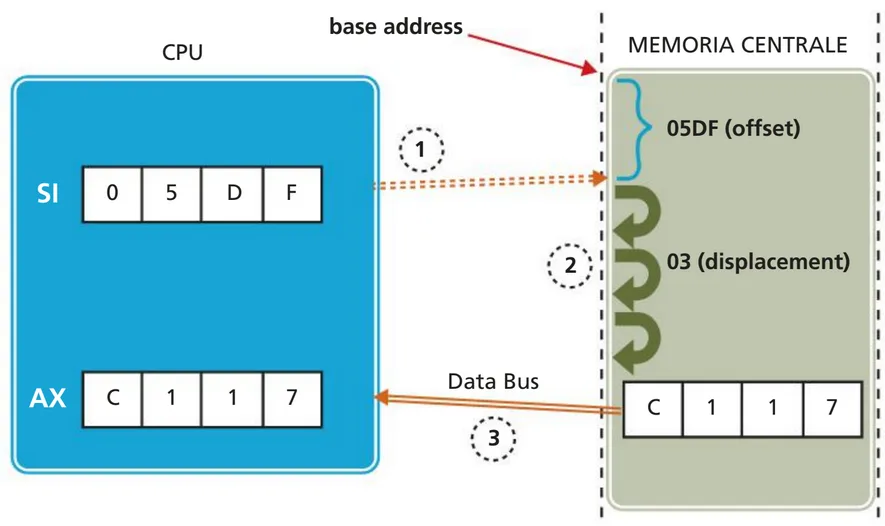
Indirizzamento indiretto tramite registro e displacement
Il displacement è un ulteriore spiazzamento rispetto all’offset L’indirizzo della locazione di memoria che contiene l’operando si ottiene spostandosi del valore di displacement specificato nell’istruzione rispetto all’indirizzo ottenuto con l’offset:
MOV AX,03[SI]
L’esecuzione di questa istruzione prevede il calcolo dell’indirizzo effettivo mediante l’operazione:
base address + source index + displacement = effective address
dove l’offset è in SI (primo passo) e lo spiazzamento “03” nell’istruzione (secondo passo). Infine (terzo passo) il valore che si trova in memoria all’offset e al displacement calcolati è copiato nel registro AX
Indirizzamento indiretto tramite registri base e indice
L’indirizzo della locazione di memoria che contiene l’operando (in questo caso il primo, cioè quello di destinazione) si ottiene sommando il contenuto del registro base (BX) con il contenuto del registro indice (DI). Quest’ultimo come al solito contiene l’offset
MOV [BX][DI],AX
L’esecuzione di questa istruzione determina prima il calcolo dell’indirizzo effettivo mediante l’operazione:
base address + destination index = effective address
Quindi, secondo passo, il valore che si trova nel registro AX viene copiato all’indirizzo di memoria calcolato

Indirizzamento indiretto tramite registri base e indice e con displacement
Un’ultima modalità prevede di aggiungere il displacement all’indirizzo ottenuto dalla somma del contenuto dei registri base e indice. L’indirizzo della locazione di memoria che contiene l’operando da copiare, per esempio in AX, si ottiene sommando il contenuto del registro base e di quello indice e poi spostandosi di tante locazioni quante specificate nell’istruzione:
MOV AX,02[BX][SI
L’esecuzione di questa istruzione determina prima il calcolo dell’indirizzo effettivo mediante l’operazione:
base address + source index + displacement = effective address
Il secondo passo prevede che all’indirizzo sia sommato lo spiazzamento “02” che si trova nell’istruzione. Infine, come terzo passo, il valore che si trova in memoria (all’offset e al displacement calcolati) è copiato nel registro AX

L’ISA (Instruction Set Architecture dell’ 8086
Le istruzioni possono essere classificate in base al loro uso. Elenchiamo le principali istruzioni per ogni tipo, con alcuni esempi di istruzioni per scrivere semplici algoritmi.
Istruzioni di utilizzo generale
- MOV: per spostare dati da memoria a CPU e viceversa;
- PUSH: per inserire un dato in cima allo stack;
- POP: per prelevare un dato dalla cima dello stack;
- XCHG: per scambiare il contenuto di due registri o di una locazione di memoria e un registro

Istruzioni per operazioni aritmetiche
- ADD: addizione;
- ADC: addizione con riporto (carry);
- SUB: sottrazione;
- SBB: sottrazione con prestito (borrow)
- MUL: moltiplicazione;
- DIV: divisione;
- INC: incremento unitario;
- DEC: decremento unitario
- NEG: negazione;
- CMP: confronto di 2 operandi con setting dei flag ZF ed SF;

Istruzioni per operazioni logiche
- AND: AND logico bitwise;
- NOT: NOT (complemento a 1);
- OR: OR logico bitwise;
- XOR: Exclusive OR logico
- Istruzioni per operazioni di rotazione e shift
- ROL: rotazione a sinistra;
- ROR: rotazione a destra;
- SHL: shift a sinistra;
- SHR: shift a destra
- Istruzioni per operazioni di trasferimento incondizionato
- CALL: chiamata a subrutine;
- RET: ritorno da subroutine;
- JMP: salti incondizionati ad una label;

Istruzioni per operazioni di trasferimento (salto) condizionato
- JG: salta se il primo operando è maggiore del secondo;
- JGE: salta se il primo operando è maggiore o uguale al secondo;
- JL: salta se il primo operando è minore del secondo;
- JLE: salta se il primo operando è minore o uguale al secondo;
- JN: salta se il primo operando è uguale al secondo;
- JNE: salta se il primo operando è diverso dal secondo;

Istruzioni per il controllo dei cicli
- LOOP: Esegue il ciclo se CX è diverso da zero;
- LOOPE: preceduta dalla CMP, esegue il ciclo se CX è diverso da 0 e il flag ZF = 0;;
- LOOPNE: preceduta dalla CMP, esegue il ciclo se CX è diverso da 0 e il flag ZF = 1;
Istruzione per caricare gli indirizzi
- LEA: (Load Effective Address): opera sugli indirizzi e consente quindi di caricare in un registro l’indirizzo di una variabile di memoria (e non il valore della variabile). Il suo utilizzo è tipico nelle stringhe per caricare l’indirizzo iniziale.;

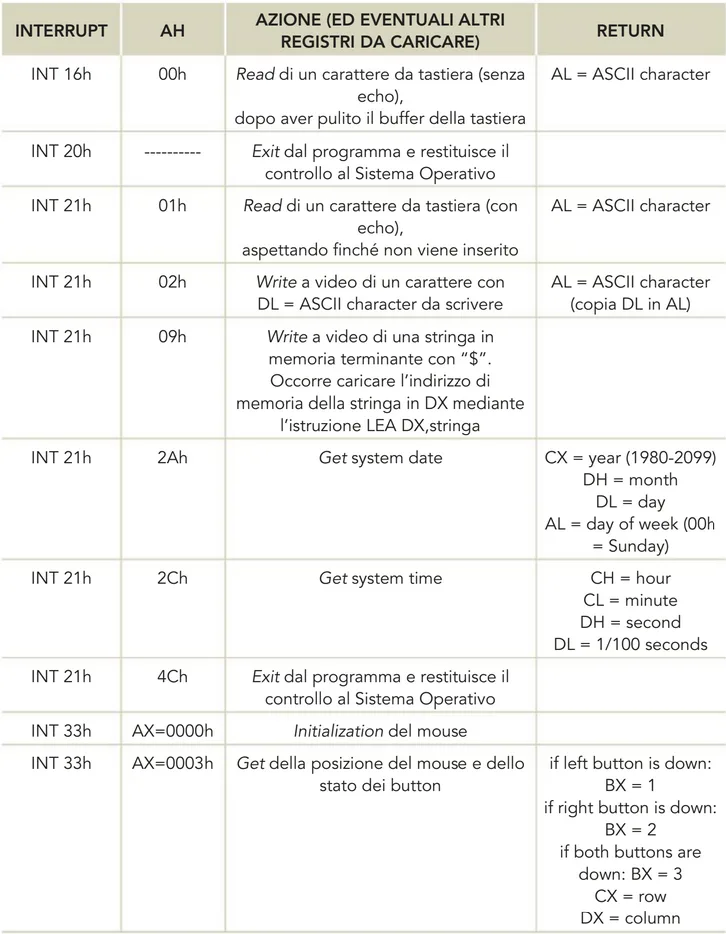
Interrupt
I programmi assembly, come i programmi scritti in linguaggio ad alto livello, consentono l’input/output dei dati mediante tastiera e video.
L’I/O coinvolge le periferiche, che comunicano con la CPU (chiedono la sua attenzione) mediante degli interrupt.
Un interrupt è un evento che interrompe il normale funzionamento della CPU. In risposta a un interrupt, la CPU sospende l’esecuzione del programma corrente ed esegue la routine di gestione dell’interrupt: interrupt handler. Al termine dell’interrupt handler, la CPU riprende l’esecuzione del programma interrotto. La presenza di un eventuale interrupt è identificata alla fine di ogni ciclo macchina.
I processori x86 gestiscono fino a 256 interrupt identificabili con un numero N da 0 a 255 in decimale (o da 00h a FEh in esadecimale) e richiamabili via software mediante l’istruzione assembly INT N.
Molti interrupt sono in grado di eseguire più servizi, cioè di far eseguire interrupt handler diversi, a seconda del contenuto precedentemente caricato nel registro di lavoro AH (parte alta di AX).

Esempi di istruzioni
| Istruzione | Indirizzamento | Descrizione | Sintassi |
|---|
| MOV | REG, memory memory, REG REG, REG memory, immediate REG, immediate SREG, memory memory, SREG REG, SREG SREG, REG | Copia operando2 in operando1. | Algoritmo: operando1 = operando2 MOV operando1, operando2 MOV – copia |
;copia il numero 34 decimale nella parte bassa del registo accumulatore
MOV AL, 34d
;AL conterrà 0x2B (34 decimale) | ADD | REG, memory memory, REG REG, REG memory, immediate REG, immediate | Aggiunge operando1 ad operando2 e il risultato è in operando1. | Algoritmo: operando1 = operando1 + operando2 ADD operando1, operando2 ADD – addizione |
MOV AL, 34d
;aggiungo 5d al contenuto di AL ed il risultato lo memorizzo in AL
ADD AL, 5d
;AL conterrà 0x27 (39 decimale) | SUB | REG, memory memory, REG REG, REG memory, immediate REG, immediate | Sottrae operando2 da operando1 e il risultato è in operando1. | Algoritmo: operando1 = operando1 – operando2 nota: se il risultato decimale è negativo AL conterrà il complemento a 2 SUB operando1, operando2 SUB – sottrazione |
MOV AL, 34d
ADD AL, 5d
;sottraggo 10d dal contenuto di AL e lo memorizzo in AL
SUB AL, 10d
;AL conterrà 0x1D (29 decimale)
SUB AL, 50d
;AL conterrà EB (complemento a 2 di -21 cioè 256-21 +1. 21d = 00010101
;--> complemento a 1 = 11101010 -->
;complemento a 2 = complemento a 1 + 1 = 11101011 = EB)
| MUL | REG memory | Se l’operando è contenuto 1 byte: Moltiplica il contenuto di AL per l’operando e il risultato è in AX. Se l’operando è contenuto 1 word: Moltiplica il contenuto di AX per l’operando e il risultato è in ( DX AX ). |
MUL registro MUL – moltiplicazione |
;operando in 1 byte
mov al, 50d
mov bl, 10d
mul bl
;AX conterrà 0x01F4 (500d)
;operando in 1 word
mov ax, 1000d
mov bx, 500d
mul bx
;(DX AX) conterrà 0x0007A120 (500000d) | DIV | REG memory | Se l’operando è contenuto 1 byte: Divide AX per l’operando e il risultato è in AX mentre il resto è in AH. Se l’operando è contenuto 1 word: Divide (DX AX) per l’operando e il risultato è in AX mentre il resto è in DX. |
DIV registro DIV – divisione |
MOV AX, 100d
MOV BX 30D
;divido 100d per 30d e ottengo 3d (0x03 contenuto in AL) con resto 10d (0x0A contenuto in AH)
;voglio dividere 100000d per 100d per ottenere 1000d
;1000000d = 0x186A0 --> carico DX con 0x0001 , AX con 86A0, BX con 100d
MOV DX, 1d
MOV AX, 0x86A0
MOV BX, 100d
DIV BX
;in AX ottengo 0x03E8 = 1000d | CMP | REG, memory memory, REG REG, REG memory, immediate REG, immediate | Confronta i due operandi per differenza: Se operando1 = operando2 pone ZF (zero flag) = 1. Se operando1 < operando2 pone CF (carry flag) = 1 e SF (sign flag) = 1. Se operando1 > operando2 non modifica i flag a meno dell’interrupt flag. |
CMP operando1, operando2 CMP – confronto |
MOV AL, 50d
MOV BL, 10d
CMP BL,AL
;CF=1 E ZF=1 | JMP | label | Salto incondizionato ad una etichetta: Tutte le istruzioni dopo JMP non vengono eseguite. |
JMP etichetta1 JMP – salto incondizionato |
MOV AL, 100d
MOV BL, 30d
JMP etichetta1
MOV AL, 35d; non viene eseguita
MOV BL, 40d; non viene eseguita
etichetta1:
MOV AL, 10d
MOV bl, 5d | INC | REG memory | Incremento unitario dell’operando. |
INC operando INC – incremento |
MOV AL, 100d
INC AL ;AL conterrà 0x65 (101d) | DEC | REG memory | Decremento unitario dell’operando. |
DEC operando DEC – decremento |
MOV AL, 100d
DEC AL ;AL conterrà 0x63 (99d) | JG | label | Usata con CMP, salta alle istruzioni successive ad un’etichetta se il primo operando è maggiore del secondo, interpretando il confronto con il segno (SF = 1 oppure CF = 1). |
JG label1 JG – salta se maggiore considerando il segno |
MOV AL, 10d
MOV BL, -30d
CMP AL,BL
JG etichetta1; AL vale 0x0A e BL vale 0xE2
MOV AL, 35d; non viene eseguita
MOV BL, 40d; non viene eseguita
etichetta1:
MOV AL, 10d
MOV bl, 5d | JA | label | Usata con CMP, salta alle istruzioni successive ad un’etichetta se il primo operando è maggiore del secondo, interpretando il confronto senza segno (SF = 0 oppure CF = 0). |
JA label1 JA – salta se maggiore non considerando il segno |
MOV AL, 10d
MOV BL, -30d
CMP AL,BL
JA etichetta1; AL vale 0x0A e BL vale 0xE2
MOV AL, 35d; viene eseguita
MOV BL, 40d; viene eseguita
etichetta1:
MOV AL, 10d
MOV bl, 5d | JL | label | Usata con CMP, salta alle istruzioni successive ad un’etichetta se il primo operando è minore del secondo, interpretando il confronto con il segno (SF = 1 oppure CF = 1). |
JL label1 JL – salta se minore considerando il segno |
MOV AL, 10d
MOV BL, -30d
CMP AL,BL
JL etichetta1; AL vale 0x0A e BL vale 0xE2
MOV AL, 35d; viene eseguita
MOV BL, 40d; viene eseguita
etichetta1:
MOV AL, 10d
MOV bl, 5d | JB | label | Usata con CMP, salta alle istruzioni successive ad un’etichetta se il primo operando è minore del secondo, interpretando il confronto senza segno (SF = 0 oppure CF = 0). |
JB label1 JB – salta se minore non considerando il segno |
MOV AL, 10d
MOV BL, -30d
CMP AL,BL
JB etichetta1; AL vale 0x0A e BL vale 0xE2
MOV AL, 35d; non viene eseguita
MOV BL, 40d; non viene eseguita
etichetta1:
MOV AL, 10d
MOV bl, 5dNOTA 1: Le istruzioni JGE, JLE, JAE, JBE sono simili alle JG, JL, JA, JB ma il salto è eseguito non se strettamente maggiore (o minore) ma se maggiore o uguale (o minore o uguale)
NOTA 2: Le istruzioni che hanno prefisso JN di fatto negano le ustruzioni con prefisso J: JNG significa jump if not greater
Ambiente di simulazione EMU8086
Per lo sviluppo di codice in linguaggio Assembly, verrà utilizzato l’EMU8086, un assemblatore che consente di simulare il microprocessore 8086 (Intel x86 e compatibile AMD). Questo ambiente permette di osservare il codice macchina di ogni istruzione Assembly, monitorando il contenuto dei registri e della memoria dopo l’esecuzione di ogni singola istruzione. I programmi che coinvolgono l’I/O aprono la finestra del DOS, rendendo interattiva l’esecuzione del codice e permettendo di inserire dati da tastiera e visualizzare il risultato sullo schermo.


Modelli di Memoria Supportati
L’8086 supporta vari modelli di memoria, che permettono di definire l’utilizzo dei segmenti per codice e dati. I formati di file più comuni utilizzati sono .com e .exe. Questi file determinano la disposizione della memoria per l’esecuzione del programma, come illustrato di seguito:
-
File .COM: Utilizza un unico segmento di 64 KB per dati e codice. I primi 256 byte sono riservati, e il programma Assembly deve iniziare da 100h. La direttiva
ORG 100himposta inizialmente IP a questo valore. Il puntatore allo stack è inizializzato a FFFEh. -
File .EXE: Il programma deve prima impostare i valori di inizio dei segmenti dati, stack e codice utilizzando le dichiarazioni
data,stackecode. Il valore di IP viene impostato a 0000. I registri DS e ES sono inizializzati tramite le istruzioni MOV.

Struttura di un Programma Assembly
Un programma Assembly può essere strutturato utilizzando Direttive Standard o Direttive Semplificate.
Direttive Standard
Le direttive standard prevedono l’utilizzo di 4 segmenti distinti per indirizzare le diverse sezioni di memoria che contengono i dati, il codice del programma e lo stack:
- Data Segment: Contiene la dichiarazione e, se necessario, l’inizializzazione delle variabili che verranno utilizzate nel programma.
- Stack Segment: Riserva l’area di memoria per l’indirizzo di ritorno dalle subroutine. È utilizzato solo nei programmi che prevedono l’uso delle subroutine.
- Code Segment: Contiene il codice Assembly scritto dal programmatore.
- Extra Segment: Fornisce un’area extra di memoria per altri scopi.
Ogni segmento termina con la parola chiave ENDS (fine segmento). Il programma termina con END nome_label, dove nome_label è la label di inizio del programma (tipicamente start).
Direttive Semplificate
Le direttive semplificate permettono una gestione più rapida della memoria, utilizzando solo 4 direttive principali:
-
.model: Definisce il tipo di segmento di memoria utilizzato e i suoi relativi comportamenti:
- tiny: Un solo segmento per dati e codice.
- small: Un segmento per il codice e uno per i dati.
- compact: Un segmento per il codice e più segmenti per i dati.
- medium: Un segmento per i dati e più segmenti per il codice.
- large: Più segmenti per i dati e per il codice.
Data Segment
In Assembly, tutte le variabili utilizzate nel programma devono essere dichiarate (e, se necessario, inizializzate) prima dell’inizio del codice vero e proprio. I tipi fondamentali di variabili sono definiti in base alle dimensioni e specificati da 5 direttive principali:
- DB (Define Byte): 1 byte
- DW (Define Word): 2 byte
- DD (Define Double-word): 4 byte
- DQ (Define Quadruple-word): 8 byte
- DT (Define Ten-byte): 10 byte
La dichiarazione di una variabile ha il seguente formato:
[nome_variabile] [direttiva] [valore/?], …, [valore/?]
Le variabili possono essere inizializzate con valori numerici o caratteri (char). Se la variabile è una stringa, si aggiunge un carattere speciale $ alla fine per indicare la fine della stringa. Le variabili non inizializzate sono seguite dal punto interrogativo (?).
Le costanti sono dichiarate utilizzando lettere maiuscole e la parola chiave EQU per inizializzarle.

Code Segment
Nel Code Segment, dopo la dichiarazione del segmento dati, si trova il segmento stack (di cui parleremo più avanti quando studieremo le subroutine), seguito dal segmento di codice vero e proprio.
La prima istruzione che si incontra nel Code Segment è una label seguita da due punti (start:), che segna l’inizio del programma. Alla label di inizio programma corrisponde l’istruzione di fine programma end nome_label (ad esempio, end start).
Dopo la label start, è necessario scrivere le istruzioni per caricare il Data Segment nel registro DS. Poiché l’Intel 8086 non consente di caricare direttamente data in DS, occorre utilizzare un registro di lavoro, tipicamente AX, come mostrato di seguito:
MOV AX, data
MOV DS, AXAl termine del programma, per restituire il controllo al sistema operativo, si utilizza la seguente istruzione:
MOV AX, 4C00h ; o in alternativa MOV AH, 4Ch
INT 21hEsercizi e Strutture di Programmazione
A seguito di questa introduzione alla struttura di un programma Assembly, verranno proposti e risolti una serie di esercizi guidati che riguardano le strutture fondamentali della programmazione, come descritto nel Teorema di Böhm-Jacopini:
- Sequenza: Esecuzione di istruzioni in ordine lineare.
- Selezione (if, if-else): Utilizzo di costrutti condizionali per decidere quale ramo del programma eseguire.
- Ciclo (while, do-while, for): Esecuzione ripetuta di un blocco di istruzioni.
Tutti gli esercizi presentati di seguito ed altri esercizi svolti possono essere scaricati dalla sezione DOWNLOAD o direttamente qui: https://profgiagnotti.it/download/7396/?tmstv=1744462456
Problema (sequenza)
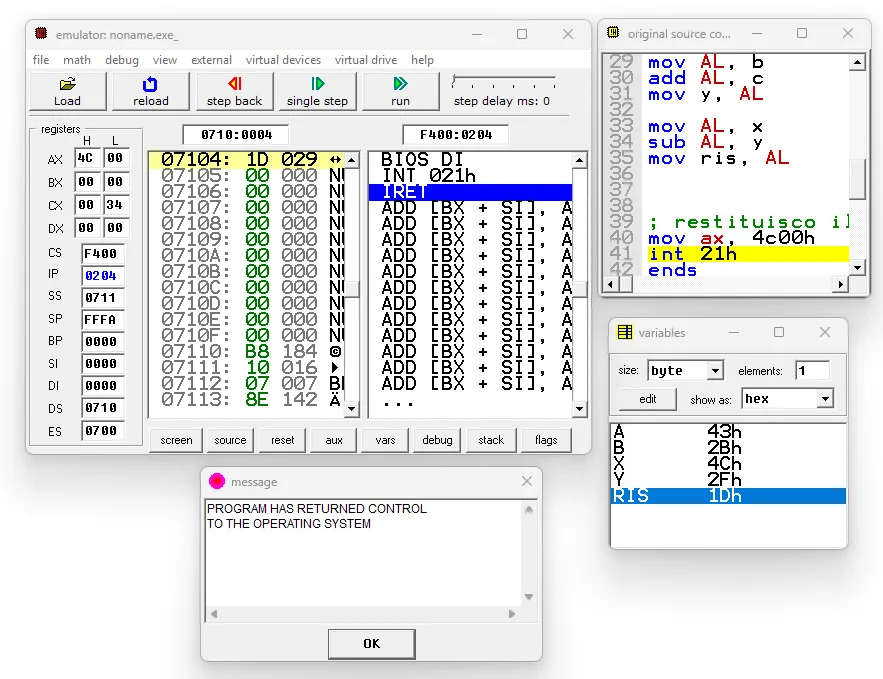
PROBLEMA: date le variabili a=67d, b=53o e le costanti C=4h e D=1001b calcolare: a + D e scrivere il risultato nella variabile x b + C e scrivere il risultato nella variabile y x-y e scrivere il risultato nella variabile ris
SOLUZIONE: scelgo di utilizzare la struttura con direttive standard e il template .exe. Nel data segment: dichiaro ed inizializzo le variabili a e b con la direttiva DB dichiaro ed inizializzo C e D con la direttiva EQU dichiaro x,y,ris
Nel code segment: copio a in AL e aggiungo D copio AL in x copio b in AL e aggiungo C copio AL in y copio x in AL e sottraggo y copio AL in ris restituisco il controllo al sistema operativo

Problema (selezione)
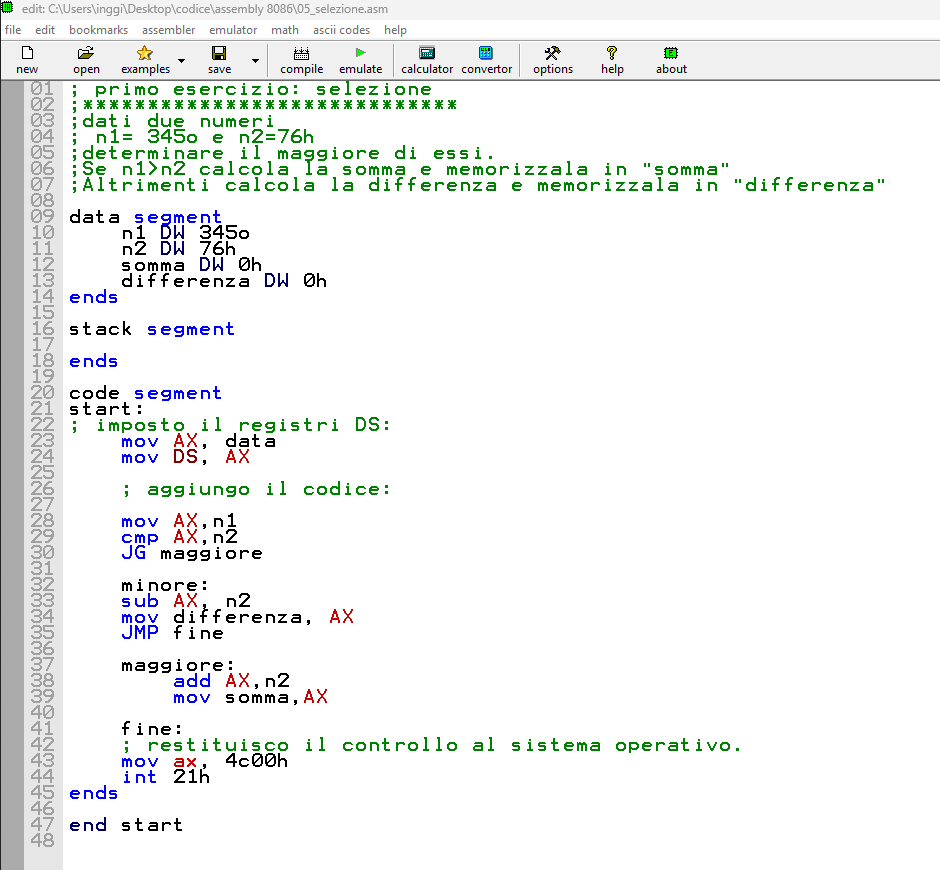
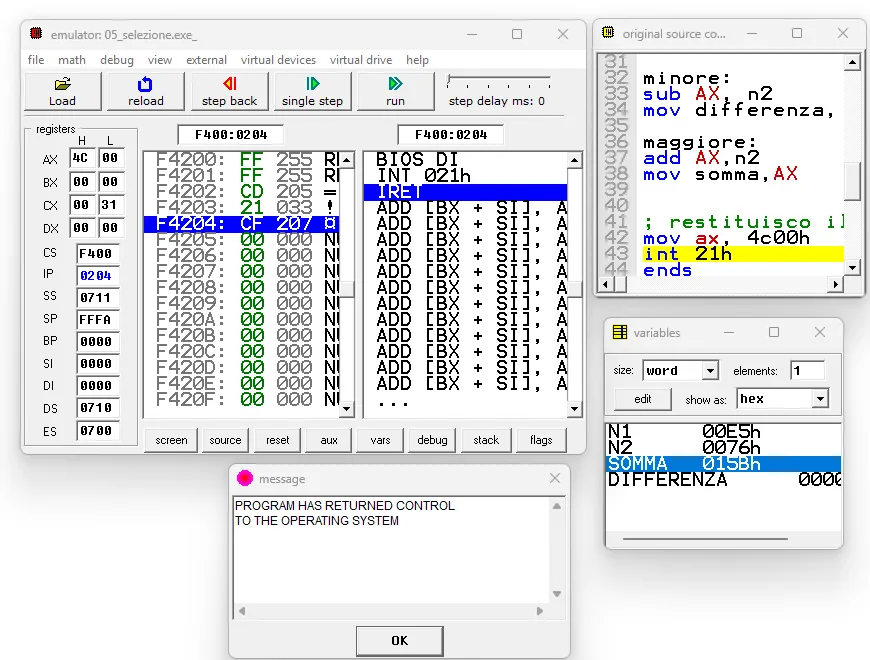
PROBLEMA: dati due numeri n1= 345o e n2=76h determinare il maggiore di essi. Se n1>n2 calcola la somma e memorizzala in “somma” Altrimenti calcola la differenza e memorizzala in “differenza”
SOLUZIONE: scelgo di utilizzare la struttura con direttive standard e il template .exe. Nel data segment: dichiaro ed inizializzo le variabili n1 e n2 con la direttiva DW dichiaro le variabili somma e differenza
Nel code segment: copio n1 in AX e lo confronto con n2 uso il JG all’etichetta maggiore se n1 è maggiore di n2 altrimenti sottraggo n2 da AX e memorizzo il risultato in differenza all’etichetta maggiore: sommo n2 ad AX e memorizzo il risultato in somma restituisco il controllo al sistema operativo
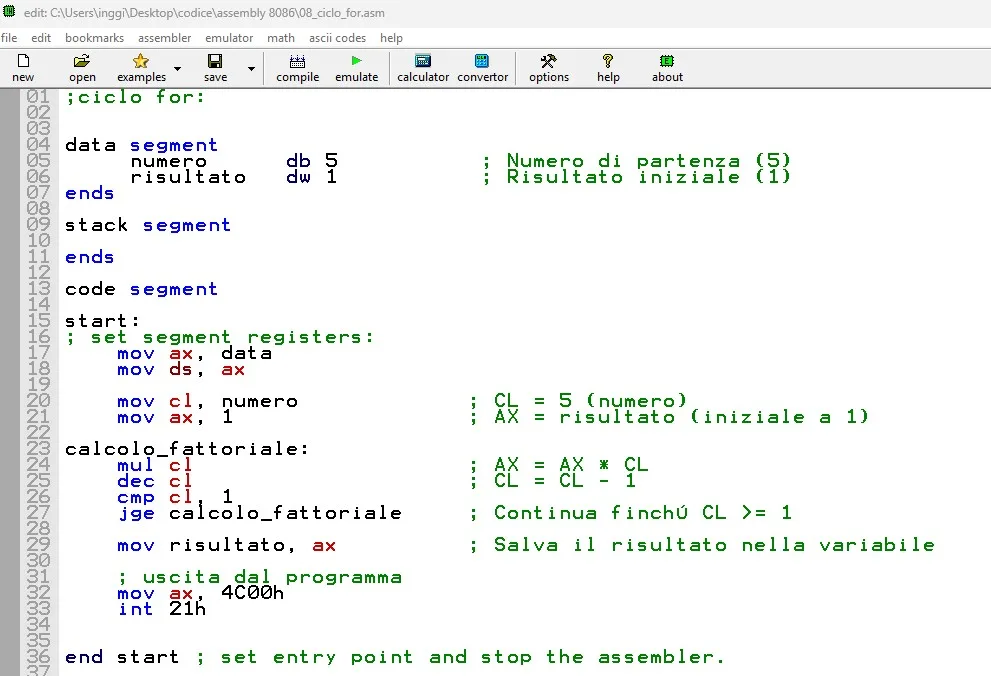
Problema (ciclo FOR)
PROBLEMA: Realizzare un programma Assembly che esegua il fattorilale di 5 simulando un ciclo FOR
SOLUZIONE: Nel data segment: inizializzo il numero a 5 ed il risultato a 1. Nel codice: inizializzo AX con il risultato iniziale, copio il numero in CL e poi inizio il ciclo: moltiplico AX = AX *CL; decremento CL, lo confronto con 1 se sono uguali termino altrimenti ricomincio il ciclo

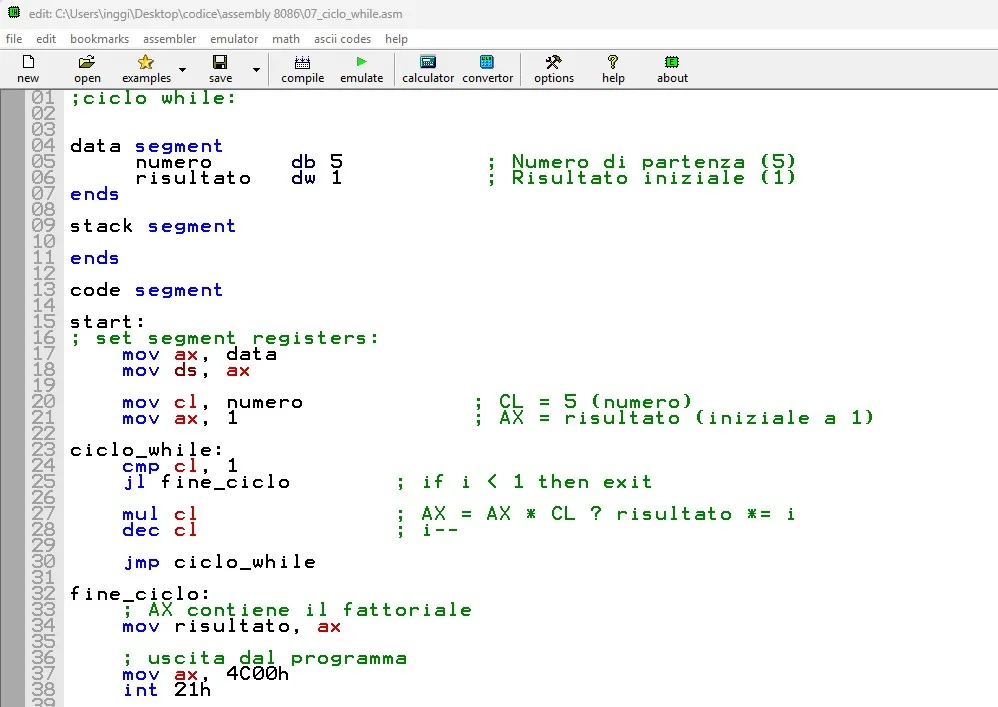
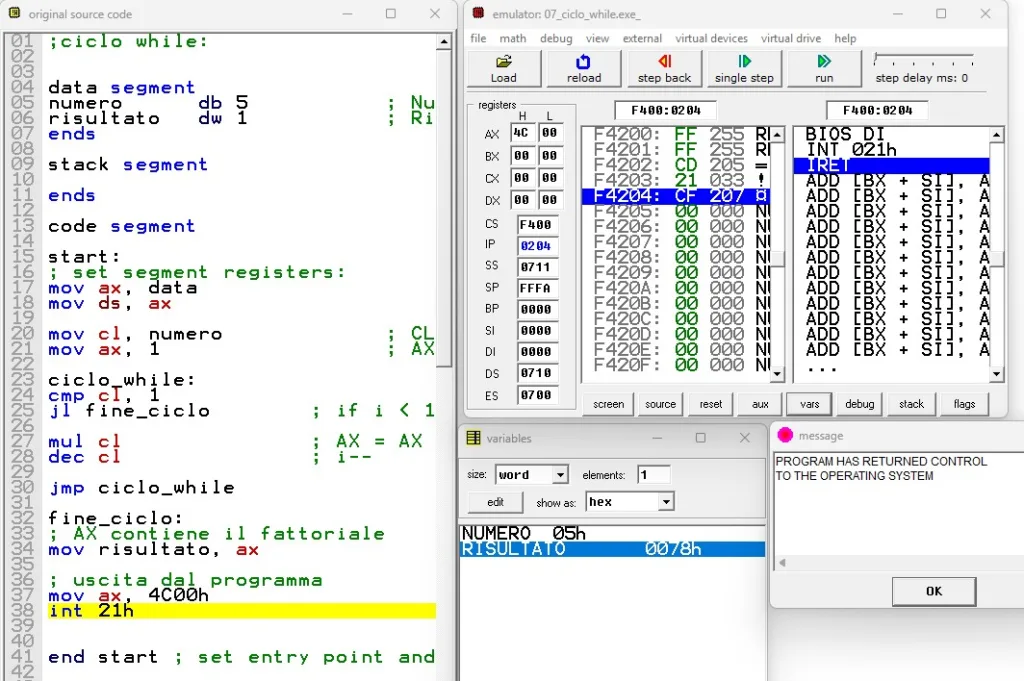
Problema (ciclo WHILE)
PROBLEMA: Realizzare un programma Assembly che esegua il fattorilale di 5 simulando un ciclo WHILE
SOLUZIONE: Nel data segment: inizializzo il numero a 5 ed il risultato a 1. Nel codice: inizializzo AX con il risultato iniziale, copio il numero in CL e poi inizio il ciclo: confronto CL con 1 se sono uguali termino altrimenti moltiplico AX = AX*CL e decremento CL
Lascia un commento