
Indice dei contenuti
- Evoluzione dell’architettura hardware
- Cluster Computing: calcolo distribuito ad alte prestazioni
- Grid Computing: cooperazione su larga scala
- Sistemi distribuiti pervasivi e reti domestiche
- Wearable Computing e reti di sensori
- Architetture Distribuite Software: Dai Terminali Remoti ai Sistemi Completamente Distribuiti
- Conclusione
In questo articolo, Evoluzione dei Sistemi Distribuiti, spiego in che modo l’evoluzione dei sistemi distribuiti ha portato a un significativo progresso nell’architettura hardware, consentendo un aumento della potenza di calcolo senza dover spingere al limite la velocità delle singole CPU. Questa evoluzione ha portato allo sviluppo di sistemi con più unità di elaborazione, noti come macchine parallele o sistemi ad architettura parallela.
Evoluzione dell’architettura hardware
Nel corso della storia dell’informatica, l’evoluzione delle architetture hardware è stata guidata dalla necessità di superare i limiti fisici e prestazionali delle singole unità di elaborazione. L’aumento della frequenza di clock delle CPU, infatti, ha incontrato rapidamente vincoli legati al consumo energetico e alla dissipazione del calore. Per questo motivo, l’attenzione si è spostata verso l’integrazione di più processori all’interno dello stesso sistema, consentendo di distribuire il carico computazionale e migliorare le prestazioni complessive.
Questa evoluzione ha portato allo sviluppo di architetture parallele e distribuite, che oggi costituiscono la base dei moderni sistemi di calcolo, dai server aziendali fino alle infrastrutture cloud e ai dispositivi intelligenti.
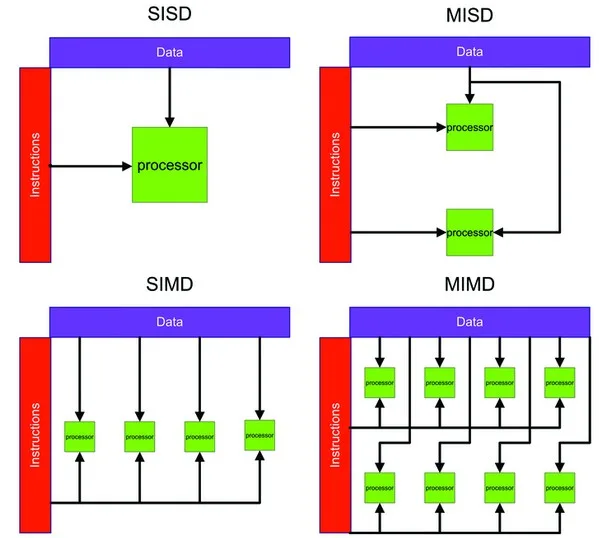
Classificazione di Flynn
Uno dei modelli più noti per classificare le architetture hardware è stato proposto nel 1972 da Michael J. Flynn. La sua classificazione si basa sull’analisi di due flussi fondamentali presenti in un sistema di calcolo:
- flusso delle istruzioni, che rappresenta l’insieme delle operazioni eseguite dalla CPU;
- flusso dei dati, che descrive il modo in cui i dati vengono elaborati durante l’esecuzione.
Combinando questi due flussi, Flynn ha individuato quattro categorie principali di architetture, ancora oggi utilizzate come riferimento concettuale.
| Tipo di Architettura | Flusso di Istruzioni | Flusso di Dati |
|---|---|---|
| SISD (Single Instruction Single Data) | Singolo | Singolo |
| SIMD (Single Instruction Multiple Data) | Singolo | Multiplo |
| MISD (Multiple Instruction Single Data) | Multiplo | Singolo |
| MIMD (Multiple Instruction Multiple Data) | Multiplo | Multiplo |
Architetture SISD
Le architetture SISD (Single Instruction Single Data) rappresentano il modello classico dei calcolatori sequenziali. Un singolo processore esegue una sola istruzione alla volta su un unico flusso di dati. Questo approccio ha caratterizzato i primi computer e molti microprocessori tradizionali.
Architetture SIMD
Nelle architetture SIMD (Single Instruction Multiple Data) una singola istruzione viene applicata simultaneamente a più flussi di dati. Questo modello è particolarmente efficace nei contesti in cui la stessa operazione deve essere eseguita su grandi quantità di dati, come nell’elaborazione grafica e nel calcolo scientifico. Le moderne GPU ne sono un esempio concreto.
Architetture MISD
Le architetture MISD (Multiple Instruction Single Data) prevedono l’applicazione di più istruzioni su un unico flusso di dati. Si tratta di una configurazione rara, utilizzata principalmente in sistemi specializzati, come alcune pipeline crittografiche o sistemi fault-tolerant.
Architetture MIMD
Le architetture MIMD (Multiple Instruction Multiple Data) sono oggi le più diffuse. Ogni processore esegue istruzioni indipendenti su insiemi di dati differenti. Questo modello è alla base dei sistemi multiprocessore, dei cluster di server e delle infrastrutture di cloud computing.
Cluster Computing: calcolo distribuito ad alte prestazioni
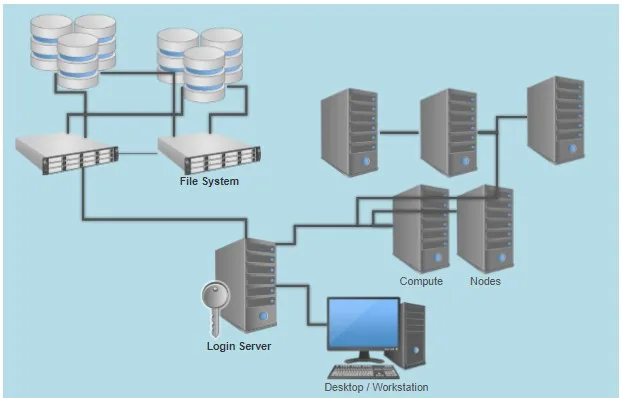
Il Cluster Computing rappresenta una forma avanzata di sistema distribuito, in cui più nodi ad alte prestazioni sono interconnessi tramite una rete locale ad alta velocità. A differenza di una semplice rete di computer, un cluster è progettato per funzionare come un unico sistema di calcolo.
I nodi di un cluster sono generalmente omogenei: condividono lo stesso hardware, lo stesso sistema operativo e la stessa rete. Questo consente di ottenere elevata potenza computazionale, trasferimenti dati rapidi e una gestione centralizzata delle risorse.
Dal punto di vista architetturale, i cluster possono essere organizzati secondo modelli diversi. Nel modello Beowulf, un nodo principale coordina l’esecuzione dei processi distribuiti sugli altri nodi, utilizzando librerie di comunicazione come MPI. Nel modello Single System Image, come nel caso di MOSIX, il cluster appare come un unico sistema operativo distribuito, con meccanismi automatici di bilanciamento del carico.
Grid Computing: cooperazione su larga scala
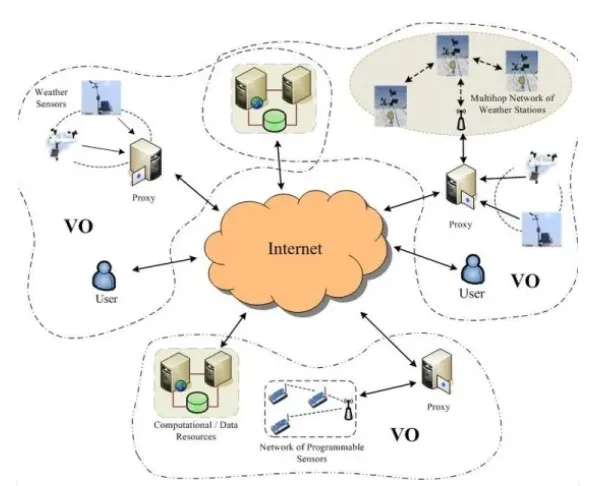
Il Grid Computing si distingue dai cluster per il suo elevato grado di decentralizzazione ed eterogeneità. I nodi di una grid possono avere hardware, sistemi operativi e politiche di sicurezza differenti e appartenere a organizzazioni diverse.
Introdotto a metà degli anni ’90, il grid computing nasce con l’obiettivo di consentire la condivisione coordinata delle risorse all’interno di organizzazioni virtuali. Non si limita alla potenza di calcolo, ma include anche storage, software, database e infrastrutture di rete.
Con il tempo, questo modello si è evoluto verso un’architettura orientata ai servizi, nota come Open Grid Service Architecture (OGSA), in cui tutte le risorse sono esposte come servizi accessibili e scalabili.
Sistemi distribuiti pervasivi e reti domestiche
I sistemi distribuiti pervasivi rappresentano una nuova generazione di soluzioni informatiche, caratterizzate da dispositivi piccoli, mobili e connessi via wireless. Essi trovano applicazione in ambiti come la domotica, la sanità digitale e le reti di sensori.
Le reti domestiche moderne sono progettate per essere auto-configuranti e facilmente gestibili. Un dispositivo centrale, come un router o un gateway domestico, collega PC, smartphone, elettrodomestici intelligenti e dispositivi IoT, rendendo possibile la realizzazione di ambienti automatizzati.
In questo contesto nasce la domotica, intesa come l’insieme di tecnologie che consentono il controllo intelligente dell’abitazione, migliorando comfort, sicurezza ed efficienza energetica. Questo approccio è strettamente legato al concetto di Ambient Intelligence, in cui l’ambiente digitale supporta attivamente l’utente nelle attività quotidiane.
L’Innovazione della Domotica
L’evoluzione tecnologica e l’integrazione sempre più stretta tra mondo fisico e digitale hanno spinto una forte crescita della domotica, un settore che si occupa dell’automazione degli ambienti domestici per migliorare la qualità della vita.
Il termine “domotica” nasce dalla fusione di “domus” (casa) e “automatica”, e si riferisce a un insieme di tecnologie che permettono il controllo intelligente della casa.
Le aspettative dei consumatori sono cambiate negli ultimi anni, con una crescente domanda di case più intelligenti e dotate di sistemi interattivi, simili a quelli presenti negli smartphone. Questo ha portato alla nascita del concetto di Ambient Intelligence (Intelligenza Ambientale), definito da D.J. Cook come:
“An Ambient Intelligence system is a digital environment that proactively, but sensibly, supports people in their lives.”
(Un sistema di intelligenza ambientale è un ambiente digitale che supporta le persone in modo proattivo ma ragionato nella loro vita.)
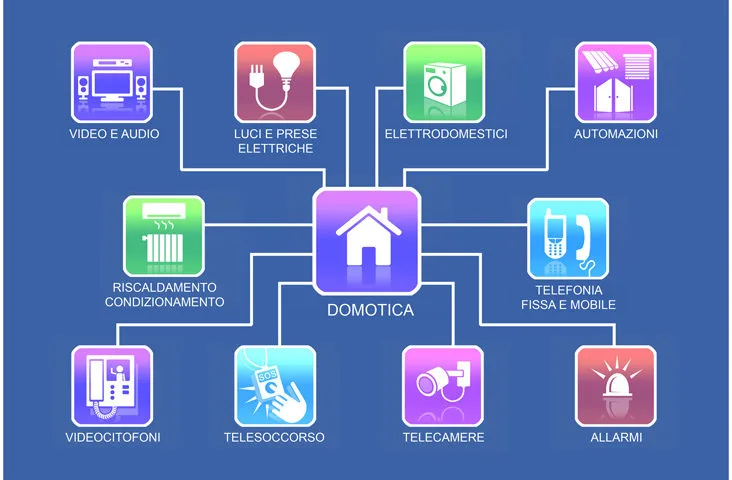
Wearable Computing e reti di sensori
Il Wearable Computing riguarda dispositivi indossabili in grado di raccogliere ed elaborare dati in tempo reale. Le applicazioni più rilevanti si trovano in ambito medico, dove è possibile monitorare parametri vitali e trasmettere informazioni a sistemi remoti o cloud.
Questi sistemi pongono importanti sfide in termini di sicurezza, privacy e gestione dei dati. La trasmissione delle informazioni deve avvenire tramite protocolli sicuri e sistemi di autenticazione affidabili, soprattutto quando si tratta di dati sanitari sensibili.
Le reti di sensori wireless svolgono un ruolo fondamentale in questo contesto, permettendo la raccolta distribuita delle informazioni e la loro elaborazione centralizzata o distribuita, a seconda delle esigenze applicative.
Applicazioni Principali
Attualmente, i sistemi di wearable computing sono prevalentemente utilizzati in ambito sanitario e medico, dove permettono il monitoraggio continuo dei parametri vitali e la gestione remota delle informazioni cliniche. Possiamo distinguere due principali modalità operative:
- Memorizzazione locale dei dati – Il dispositivo raccoglie i dati e li archivia in un computer palmare (PDA, Personal Digital Assistant) o in uno smartphone.
- Trasmissione remota dei dati – I dati vengono inviati a un sistema di archiviazione remoto o a un’infrastruttura cloud, permettendo l’accesso in tempo reale da parte di operatori sanitari.

Sfide Tecnologiche e di Sicurezza
Nonostante i progressi tecnologici, i dispositivi wearable presentano alcune sfide critiche:
- Memorizzazione e gestione dei dati: i dispositivi devono garantire un’adeguata capacità di archiviazione senza compromettere le prestazioni.
- Prevenzione della perdita di dati: meccanismi di backup e sincronizzazione sono fondamentali per evitare la perdita di informazioni cruciali.
- Sicurezza e privacy: la trasmissione dei dati sanitari deve avvenire tramite protocolli criptati e con sistemi di autenticazione sicuri.
- Gestione degli allarmi: in caso di rilevamento di valori anomali (es. battito cardiaco irregolare), il sistema deve attivare notifiche immediate per medici o familiari.
Reti di Sensori e Integrazione con il Wearable Computing
Le reti di sensori (Wireless Sensor Networks – WSN) sono un elemento chiave nei sistemi di wearable computing. Sono composte da numerosi nodi sensore (da 10 a 1000) che raccolgono informazioni sull’ambiente o sul corpo umano.
Due possibili approcci per la gestione dei dati raccolti dai sensori:
- Base di dati centralizzata: i dati vengono inviati a un server remoto o a un’infrastruttura cloud per essere elaborati.
- Memorizzazione distribuita: ogni nodo della rete può memorizzare parte delle informazioni, creando di fatto un database distribuito.
Questa seconda opzione è particolarmente utile in contesti in cui la connettività è intermittente o quando si vuole ridurre la dipendenza da un unico punto di raccolta dati.
Architetture Distribuite Software: Dai Terminali Remoti ai Sistemi Completamente Distribuiti
L’evoluzione dei sistemi distribuiti non ha interessato esclusivamente l’hardware, ma ha coinvolto in modo profondo anche il software. In molti casi, infatti, le architetture software hanno anticipato i cambiamenti nei sistemi operativi e nelle infrastrutture di rete, introducendo nuovi modelli di cooperazione tra applicazioni e risorse.
Analizzare l’evoluzione delle architetture software distribuite consente di comprendere come si sia passati da sistemi rigidamente centralizzati a soluzioni flessibili, scalabili e cooperative, che costituiscono oggi la base delle applicazioni moderne.
Architettura a Terminali Remoti
a prima forma di architettura distribuita si basa sull’utilizzo di terminali remoti collegati a un’unica entità centrale. In questo modello, il sistema centrale esegue interamente le operazioni di elaborazione, mentre i terminali sono dispositivi passivi, privi di capacità computazionale autonoma.
I terminali si limitano a inviare input all’elaboratore centrale e a ricevere in output i risultati delle elaborazioni. Ogni sessione utente è gestita separatamente, con un’area di memoria dedicata, ma il controllo rimane totalmente accentrato.
Questa architettura presenta alcune caratteristiche ben definite:
- terminali omogenei e con funzionalità estremamente limitate;
- elaborazione completamente centralizzata;
- forte dipendenza da un unico punto di calcolo;
- bassa scalabilità e ridotta tolleranza ai guasti.
Nonostante i suoi limiti, questo modello ha rappresentato una soluzione efficace nelle prime fasi dell’informatica, soprattutto in contesti aziendali e istituzionali.
Architettura Client-Server
L’architettura client-server nasce come naturale evoluzione del modello a terminali remoti. In questo caso, i client acquisiscono capacità di elaborazione locale e diventano entità attive, in grado di formulare richieste e di interagire con uno o più server.
Il server fornisce servizi specifici, come l’accesso ai dati, l’elaborazione di informazioni o la gestione delle risorse, mentre il client si occupa dell’interfaccia utente e di parte della logica applicativa.
Questo modello introduce numerosi vantaggi:
- maggiore scalabilità rispetto ai sistemi centralizzati;
- possibilità di distribuire i servizi su più server specializzati;
- interoperabilità tra client e server basati su tecnologie differenti;
- flessibilità nella progettazione delle applicazioni.
Un aspetto rilevante dell’architettura client-server è che un server può, a sua volta, comportarsi come client di un altro server, dando origine a una rete di servizi interconnessi e cooperanti.
Architettura Web-Centric
La diffusione del Web ha portato allo sviluppo delle architetture Web-centric, nelle quali le applicazioni risiedono prevalentemente sui server e i client svolgono il ruolo di interfaccia di accesso ai servizi.
In questo modello, il browser Web diventa lo strumento principale di interazione, consentendo agli utenti di accedere alle applicazioni senza la necessità di software dedicato. Le applicazioni gestionali e i servizi aziendali vengono progressivamente migrati verso piattaforme Web.
Le architetture Web-centric possono essere suddivise in due grandi categorie:
- architetture Web tradizionali, basate su pagine HTML statiche o con interazioni limitate;
- architetture Web multilivello, che separano la logica di presentazione, la logica applicativa e la gestione dei dati.
Questa separazione consente una maggiore manutenibilità del software e una migliore distribuzione dei carichi di lavoro.
Architettura Cooperativa
L’architettura cooperativa rappresenta un’ulteriore evoluzione del modello client-server. In questo approccio, le entità software sono considerate componenti autonomi, in grado sia di offrire sia di richiedere servizi.
Il concetto di cooperazione supera le tradizionali distinzioni tra client e server e si basa su standard di comunicazione che consentono l’interoperabilità tra sistemi eterogenei, indipendentemente dall’hardware, dal sistema operativo o dai protocolli di rete utilizzati.
Un esempio significativo è rappresentato da CORBA (Common Object Request Broker Architecture), che consente a componenti distribuiti di comunicare come se fossero oggetti locali, favorendo modularità e riusabilità del software.
Architettura Completamente Distribuita
Nell’architettura completamente distribuita non esiste un server centrale. Le entità del sistema sono paritetiche e cooperano direttamente tra loro, come avviene nei sistemi di tipo groupware o peer-to-peer.
Questo modello è caratterizzato da:
- assenza di un punto centrale di controllo;
- elevata ridondanza delle risorse;
- maggiore tolleranza ai guasti;
- distribuzione efficace dei carichi di lavoro.
Tra le tecnologie associate a questo approccio troviamo:
- gli standard promossi dall’Object Management Group (OMG);
- RMI (Remote Method Invocation) per la comunicazione tra processi Java distribuiti;
- DCOM (Distributed Component Object Model), sviluppato da Microsoft per la comunicazione tra componenti distribuiti.
Architettura a livelli
Per ridurre il carico elaborativo sui server e migliorare la modularità del software, sono state introdotte le architetture multilivello, nelle quali le funzionalità applicative sono suddivise in più livelli logici.
In questo contesto si colloca il middleware, uno strato software intermedio che si posiziona sopra il sistema operativo e sotto le applicazioni. Il middleware rappresenta un’evoluzione dei sistemi operativi distribuiti e ha lo scopo di gestire la complessità tipica dei sistemi distribuiti.
Secondo D.E. Bakken, il middleware è un insieme di tecnologie software progettate per assistere gli sviluppatori nella gestione dell’eterogeneità e della complessità dei sistemi distribuiti. Esso facilita la comunicazione e l’interazione tra componenti software distribuiti, creando un’architettura a tre livelli.
Il middleware può variare da host a host e fornisce un insieme di servizi comuni che verranno approfonditi in modo più dettagliato nelle sezioni successive.
Obiettivi del Middleware
Il principale obiettivo del middleware è garantire l’interoperabilità tra applicazioni che operano su sistemi operativi differenti. Inoltre, consente la connettività tra servizi che devono collaborare all’interno di piattaforme distribuite, offrendo API e meccanismi di programmazione relativamente semplici.
Grazie al middleware, i sistemi distribuiti risultano più facilmente programmabili e possono adottare specifici modelli di interazione, come:
- la chiamata di procedure remote (RPC);
- lo scambio di messaggi tra processi distribuiti.
Funzionalità del Middleware
Il middleware offre numerose funzionalità di supporto, tra cui:
- servizi di astrazione e cooperazione;
- servizi per le applicazioni;
- servizi di amministrazione del sistema;
- servizi di comunicazione;
- ambienti di sviluppo applicativo.
Secondo Bernstein, un servizio di middleware è un servizio general-purpose che si colloca tra le piattaforme e le applicazioni, fungendo da elemento di collegamento tra i diversi livelli del sistema.
Limiti del Middleware
Nonostante i numerosi vantaggi, il middleware non rappresenta una soluzione universale a tutti i problemi dei sistemi distribuiti. Le principali criticità derivano spesso da scelte progettuali poco accurate o da una comprensione incompleta dei meccanismi di funzionamento.
In particolare, molti sviluppatori non distinguono correttamente tra una chiamata di procedura locale e una chiamata di procedura remota, con conseguenze negative sulle prestazioni e sull’affidabilità del sistema.
Inoltre, il middleware si occupa prevalentemente della comunicazione tra componenti e non gestisce direttamente i malfunzionamenti applicativi, i guasti dei server o i problemi di rete. La gestione degli errori e delle condizioni di fault rimane quindi una responsabilità dell’applicazione..
Conclusione
L’evoluzione delle architetture hardware e software ha portato alla realizzazione di sistemi distribuiti sempre più complessi, efficienti e scalabili. Dai primi calcolatori centralizzati fino ai moderni sistemi cloud ed edge, l’obiettivo rimane lo stesso: offrire maggiore potenza di calcolo, affidabilità e flessibilità.
In un contesto tecnologico in continua evoluzione, comprendere queste architetture è fondamentale per progettare sistemi informatici sicuri, performanti e adatti alle esigenze del mondo digitale moderno.
Lascia un commento