
In questo articolo, Application Layer e HTTP, analizziamo il livello applicativo dello stack TCP/IP ed il protocollo HTTP. Descriviamo infine come avviene, in generale la comunicazione sul WEB
Indice dei contenuti
- Introduzione
- Il livello di applicazione nello stack TCP/IP
- Sicurezza e crittografia
- Architettura client-server
- Il Protocollo HTTP
- Esercizi pratici
- Conclusione
Introduzione
Le reti di computer non si limitano a trasportare dati da un punto all’altro, ma forniscono servizi complessi utilizzati quotidianamente: navigazione Web, posta elettronica, streaming, cloud e applicazioni distribuite.
Tutti questi servizi operano a livello software grazie al livello di applicazione (Application Layer), che rappresenta l’interfaccia tra l’utente e l’infrastruttura di rete.
Per uno studente di Sistemi e Reti, comprendere questo livello significa capire come funzionano realmente le applicazioni Internet, andando oltre l’hardware e i collegamenti fisici.
Il livello di applicazione nello stack TCP/IP
Nello stack TCP/IP, il livello di applicazione è lo strato più alto dell’architettura e raccoglie tutte le funzionalità necessarie affinché un programma possa comunicare tramite la rete.
A differenza del modello ISO/OSI, che distingue più livelli superiori, TCP/IP adotta un approccio più pratico e orientato all’implementazione reale.
Compiti del livello di applicazione
Il livello di applicazione si occupa di:
- definire protocolli applicativi standard;
- stabilire formati e significato dei messaggi scambiati;
- consentire la comunicazione tra processi applicativi su host diversi;
- offrire servizi di rete alle applicazioni utente.
È importante sottolineare che non tutte le applicazioni Internet sono protocolli: il protocollo definisce le regole, mentre l’applicazione le utilizza.
Sicurezza e crittografia
Con l’introduzione della crittografia, il livello applicativo può anche:
- utilizzare algoritmi crittografici per garantire riservatezza e integrità dei dati;
- gestire autenticazione e controllo degli accessi.
📌 Da ricordare
- Il livello di applicazione è il più vicino all’utente
- Definisce come comunicano le applicazioni
- Può integrare sicurezza e crittografia
Protocolli applicativi e protocolli di trasporto
I protocolli applicativi si appoggiano ai protocolli di trasporto TCP o UDP, scegliendo quello più adatto al servizio offerto.
Protocolli basati su TCP
TCP garantisce affidabilità, controllo degli errori e ordine dei pacchetti. È utilizzato quando l’integrità dei dati è fondamentale:
- HTTP: trasferimento delle risorse Web;
- FTP: trasferimento di file;
- SMTP: invio della posta elettronica;
- POP3 e IMAP: ricezione delle email;
- SSH e Telnet: accesso remoto ai sistemi;
- DHCP: assegnazione dinamica dei parametri di rete.
Protocolli basati su UDP
UDP privilegia velocità e bassa latenza, rinunciando al controllo degli errori:
- DNS, per la risoluzione rapida dei nomi;
- servizi di streaming audio/video;
- applicazioni di voice over IP.
Architettura client-server
Il modello client-server è il paradigma fondamentale delle applicazioni di rete.
In questo modello:
- il client invia richieste;
- il server resta in ascolto e risponde fornendo servizi o risorse.
Client e server non vanno intesi come macchine fisiche, ma come processi in esecuzione.
Il Client:
- ✅ È un processo attivo
- ✅ Inizia la comunicazione
- ✅ Usa un URL (Uniform Resource Locator) per identificare la risorsa
- ✅ Specifica un indirizzo IP e un numero di porta del servizio desiderato
- ✅ Attende una risposta dal server
Il Server:
- ✅ È un processo passivo
- ✅ Rimane in ascolto su una porta TCP
- ✅ Fornisce risposte HTTP
- ✅ Può restituire risorse o messaggi di errore (es. 404 Not Found)
📌 Esempio
Un server HTTP resta in ascolto sulla porta 80 in attesa delle richieste dei client.
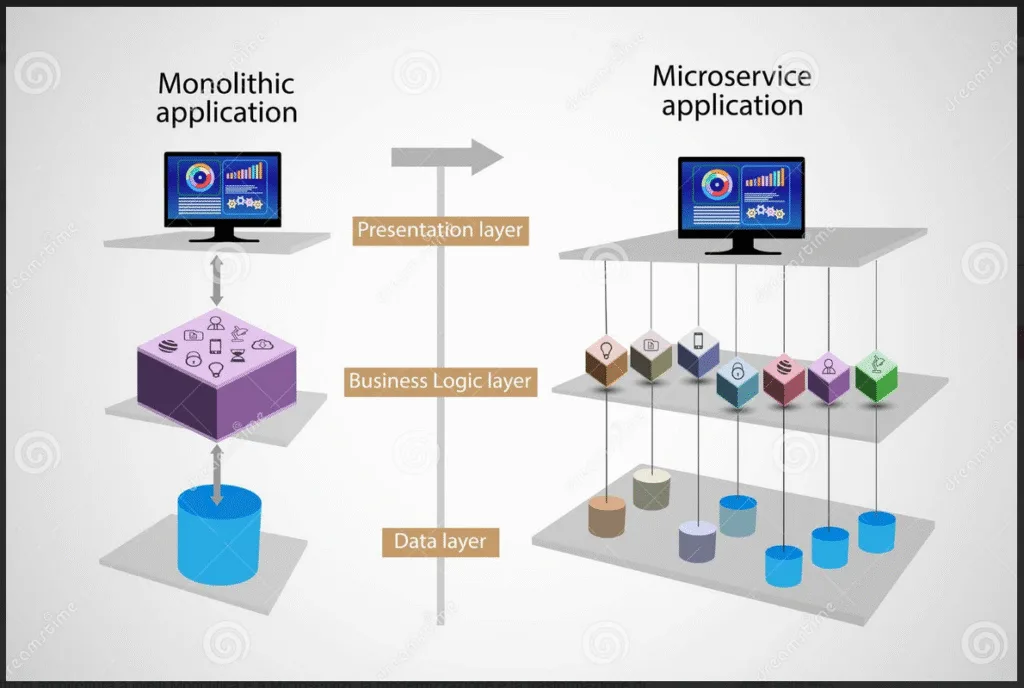
Evoluzione delle architetture applicative
Nel tempo, le applicazioni si sono evolute:
- Applicazioni single-tier: tutto risiede sullo stesso sistema (oggi poco diffuse);
- Architetture two-tier: client e server distinti, tipiche dei primi sistemi di rete;
- Architetture multi-tier: suddivisione in più livelli (presentazione, logica applicativa, dati).
Questa separazione migliora la gestione del software e la sicurezza.
Microservizi e API REST
Nelle applicazioni moderne Web e cloud si utilizzano architetture multilayer basate su microservizi.
Ogni microservizio:
- svolge una funzione specifica
- comunica tramite API REST
- può agire da client o server
Un’API REST (Representational State Transfer) è uno stile per la progettazione di servizi web che permette a diverse applicazioni di comunicare tra loro su una rete, seguendo un insieme di regole per rendere le interazioni semplici, scalabili e standardizzate, utilizzando comunemente i metodi HTTP (GET, POST, PUT, DELETE) per gestire risorse e stati, tipicamente in formato JSON o XML, con richieste stateless (senza stato)
Le API REST permettono:
- interoperabilità tra sistemi diversi;
- utilizzo di linguaggi e piattaforme differenti;
- sviluppo modulare e scalabile.
Questo approccio è oggi uno standard nello sviluppo di applicazioni distribuite.
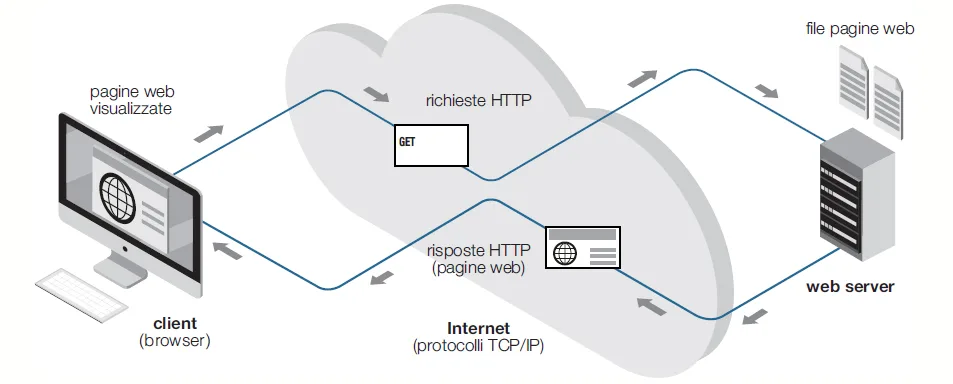
Il Protocollo HTTP
Una volta compreso il modello client-server, possiamo analizzare il protocollo HTTP (HyperText Transfer Protocol), che rappresenta il principale meccanismo di comunicazione del Web.
Il protocollo HTTP (HyperText Transfer Protocol) è alla base della comunicazione Web e consente lo scambio di risorse tra client e server.
Caratteristiche principali del protocollo HTTP
- Utilizzo del paradigma Client/Server
- Utilizzo della porta 80: I server HTTP rimangono in ascolto su questa porta, in attesa di richieste dai client
- Scambio di risorse: inizialmente progettato per lo scambio di pagine WEB oggi è largamente utilizzato per lo scambio di risorse quali file, immagini o altre forme di informazione
- Identificazione tramite URI (Uniform Resource Identifier): stringa contenenti l’identificatore univoco di una risorsa
- Utilizzo di Metodi o Verbi: operazioni eseguibili sulle risorse
- Comunicazione stateless
Struttura di una HTTP Request
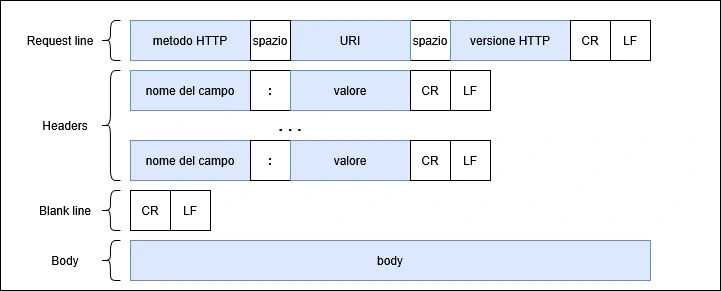
La prima riga è obbligatoria e contiene tre dati separati da uno spazio (Codice ASCII 20hex):
- Metodo: operazione da eseguire sulla specifica risorsa
- URI: per identificare la risorsa
- Versione del protocollo
Al termine della prima riga abbiamo CRLF (Carriage Return + Line Feed) è una sequenza di due caratteri di controllo per indicare la fine di una riga di testo, combinando il movimento del cursore all’inizio della riga (CR, codice ASCII 13) e lo spostamento alla riga successiva (LF, codice ASCII 10). Corrisponde a invio a capo
Gli header HTTP sono metainformazioni che vengono scambiate tra client e server. possono essere zero o più di una. Ogni riga ha la forma: nome del campo: valore
Questi header possono riguardare:
-
Informazioni generali sulla trasmissione, come il tipo di compressione (es.
Transfer-Encoding). -
Caratteristiche dell’entità trasmessa, come il tipo di contenuto (es.
Content-Type) o la data di scadenza della risorsa (es.Expires). -
Dettagli relativi alla richiesta, come il
User-Agent(che indica il browser utilizzato) o l’host richiesto. -
Dettagli sulla risposta generata dal server, come il tipo di server (es.
Server) o le modalità di autenticazione richieste (es.WWW-Authenticate).
Dopo gli header abbiamo una riga vuota e dopo la riga vuota abbiamo il body, il corpo del messaggio che, per alcuni metodi non serve per altri metodi è necessario a formare correttamente la request
Esempio di richiesta HTTP completa
Copied!GET /profgiagnotti.it/learn HTTP/1.1 Accept: image/gif, image/jpeg, image/png, */* Accept-Language: it Accept-Encoding: gzip, deflate If-Modified-Since: Fri, 14 Mar 2025 10:54:03 GMT User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0)
HTTP Response
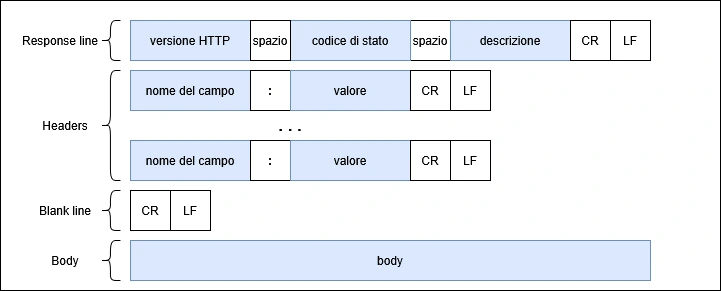
La struttura è molto simile alla richiesta ma il primo campo presenta versione del protocollo utilizzata mentre il secondo campo contiene il codice di stato, un codice a tre cifre che indica l’esito della richiesta. L’ultimo campo della prima linea contiene la descrizione del codice di stato.
Il resto della struttura è identica. Ovviamente nel body ci sarà la risposta inviata dal server al client
Esempio di una Response HTTP
Un esempio di intestazione tipica di una risposta HTTP potrebbe essere:
Copied!HTTP/1.1 200 OK Transfer-Encoding: chunked Date: Sat, 28 Nov 2021, 04:33:04 GMT Server: Apache/1.4 Connection: close Expires: Sat, 28 Nov 2021, 05:33:04 GMT Cache-Control: max-age=3600, public Content-Type: text/html
Nel corpo della risposta (body), troviamo il contenuto richiesto, ad esempio una pagina HTML:
Copied!<HTML> <HEAD> <TITLE>Il protocollo HTTP</TITLE> </HEAD> <BODY> <h1>Benvenuti alla lezione sul protocollo HTTP!</h1> <p>Questo è un esempio di risposta HTTP con un corpo HTML.</p> </BODY> </HTML>
l’URI (Uniform Resource Identifier)
E’ un identificatore univoco di una risorsa. E’ costituito da:protocollo://indirizzo/nome della risorsa
Un’esempio di URI è https://profgiagnotti.it/index.html
Il protocollo è quello utilizzato dal client per effettuare la richiesta
l’indirizzo rappresenta o un indirizzo IP o il nome dell’host che contiene la risorsa
La risorsa può essere un percorso che consente di raggiungere uno o più risorse specifiche
I Metodi HTTP
I metodi HTTP (noti anche come “verbi”) rappresentano l’intenzione del client nella richiesta inviata al server. I più comuni includono:
- GET: Richiede una risorsa dal server (es. una pagina web).
- POST: Invia dati al server per la creazione o l’aggiornamento di risorse.
- PUT: Carica o aggiorna una risorsa sul server.
- DELETE: Rimuove una risorsa dal server.
Questi metodi sono essenziali per il funzionamento delle applicazioni web, specialmente quelle basate su architetture RESTful, che utilizzano i metodi CRUD (Create, Read, Update, Delete) per gestire le risorse.
📌 Riepilogo CRUD
- Create → POST
- Read → GET
- Update → PUT
- Delete → DELETE
Dopo aver analizzato i principali metodi HTTP, la tabella seguente ne riepiloga le caratteristiche fondamentali.
| Metodo | Descrizione |
|---|---|
| GET | Richiede una risorsa dal server (es. una pagina HTML). |
| POST | Invia dati al server per la creazione o aggiornamento di risorse. |
| PUT | Carica o aggiorna una risorsa sul server. |
| DELETE | Rimuove una risorsa dal server. |
Passaggio dei parametri con metodi GET e POST
Nelle richieste dei client i parametri occupano una posizione diversa in base al metodo utilizzato:
- Utilizzando GET i parametri sono visibili nella barra degli indirizzi e concatenati all’URL e separati dal carattere ?. La query string è costituita da
nome del parametro = valoree se si passano più parametri essi vengono separati dal carattere &. di seguito un esempio:GET www.sito.it/index.php?nome=mario&cognome=giagnotti
- Utilizzando POST i parametri non sono visibili nella barra degli indirizzi ma vengono passati attraverso il body della richiesta. Apparentemente non sono visibili
-
POST www.sito.it/index.php
nome=mario&cognome=giagnotti
-
La Codifica URL
La codifica URL (URL encode) è il processo di trasformazione di una stringa di testo in un formato che può essere trasmesso attraverso una richiesta HTTP. La codifica è particolarmente utile quando si inviano dati tramite metodi GET o POST, specialmente per campi modulo HTML.
Ad esempio, una stringa come societa=Rossi & Martini diventa societa=Rossi%26Martini dopo essere stata codificata. I caratteri speciali come &, %, e spazi vengono sostituiti con sequenze di caratteri specifiche per garantire che la stringa sia valida all’interno di un URL.
La URL encode è una procedura che prepara opportunamente una stringa di dati, codificandola, in modo che venga riconosciuta durante la trasmissione HTTP con metodo GET o POST. Questo tipo di codifica viene utilizzata nelle QueryString per inserire, all’interno delle URL, delle stringhe di testo in modo sicuro e conforme allo standard previsto per le URL
La codifica URL viene applicata anche nel caso in cui la richiesta venga generata, per esempio, da un link HTML (tag <a href>) e non solo da campi di un modulo (tag <form>). Vediamo i passaggi che devono essere effettuati per codificare la stringa da inviare. La stringa da inviare è sempre formata da una serie di coppie nome_campo e valore. Le operazioni da fare sono le seguenti:
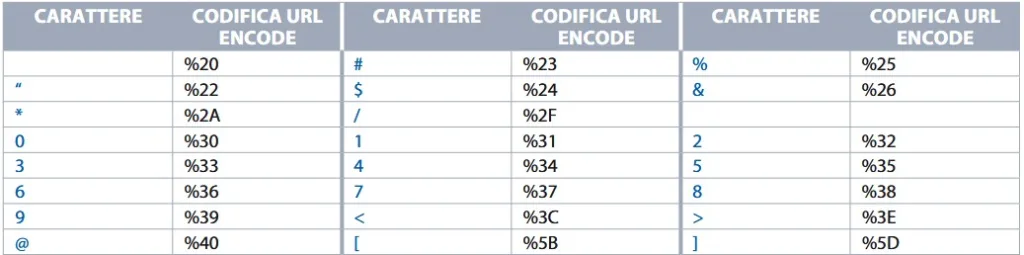
- convertire tutti i caratteri non sicuri presenti nella stringa in simboli formati dalla percentuale e dal codice ASCII relativo: %xx, dove xx è il valore ASCII del carattere, in esadecimale. I caratteri non sicuri includono =, &, %, @, spazio, +, e altri caratteri non stampabili
- eliminare gli spazi vuoti sostituendoli con il carattere %20
- unire i nomi e valori con uguale (=) e separare i nomi con ampersand (&), per esempio:
Vediamo una tabella che riepiloga i principali caratteri di URL encode:
I Codici di Stato HTTP
I codici di stato HTTP sono utilizzati dai server per comunicare l’esito di una richiesta. I codici sono suddivisi in cinque classi principali:
- 1xx (Informativi): Indicano che la richiesta è stata ricevuta e il processo è in corso.
- 2xx (Successo): Indicano che la richiesta è stata completata con successo.
- 3xx (Redirezione): Indicano che il client deve intraprendere un’azione ulteriore per completare la richiesta.
- 4xx (Errore Client): Indicano che c’è un problema con la richiesta inviata dal client.
- 5xx (Errore Server): Indicano che c’è un problema con il server durante l’elaborazione della richiesta.

HTTP Stateless. Cookie e session
Il protocollo è stateless cioè il server , una volta inviata la risposta, non mantiene memoria di quanto richiesto dal client.
A volte però risulta essere necessario mantenere memoria delle scelte fatte da un utente affinchè egli non debba effettuarle ogni volta.
La soluzione si ottiene attraverso 2 tecniche:
Cookies:
- sono file di testo memorizzati sul dispositivo del client e vengono scambiati con il server come Header HTTP
- sono regolati dal GDPR
- la durata di un cookie è impostata come parametro alla creazione
- hanno una dimensione massima di 4KB
- possono essere eliminati dagli utenti attraverso le impostazioni del browser
Sessions:
- sono file salvati sul server e possono essere conservati per tutto il tempo in cui l’utente mantiene viva la sessione di lavoro
- la durata massima è specificata nei file .php (o comunque in file sul server)
- non c’è una dimensione massima
- La cancellazione va fatta lato server
Evoluzione: HTTP/2 e HTTP/3
La versione HTTP /1.0 prevedeva connessioni non persistenti cioè per ogni richiesta HTTP veniva aperta e chiusa una connessione TCP. Se una pagina conteneva 3 immagini era necessario stabilire 3 connessioni TCP e 3 richieste con notevole dispendio di tempo
Dalla versione HTTP /1.1 è stato possibile utilizzare connessioni persistenti o senza pipeline (richieste HTTP “seriali” su un’unica connessione TCP) oppure con pipeline (aperta la connessione il client invia “in parallelo” richieste senza attendere la risposta dal server)
Attualmente le versioni HTTP più utilizzate sono HTTP /1.1 e HTTP /2. Ci sono state evoluzioni del protocollo tra le quali:
- HTTP/2 introduce multiplexing, maggiore efficienza e cifratura (utilizzato con TLS per ottenere il protocollo sicuro HTTPS)
- HTTP/3 utilizza QUIC su UDP, riducendo la latenza e migliorando le prestazioni su reti moderne ma non è ancora tanto diffuso
Esercizi pratici
Vogliamo interagire con un servizio API REST gratuito, JSONPlaceholder, per testare l’utilizzo dei metodi HTTP (richiedere risorse e ricevere risposte).
JSONPlaceholder offre diverse risorse (/posts , /albums, /todos, /comments, /photos, /users
step 1:
- scaricare POSTMAN (o utilizzare l’estensione Thunder Client di Visual Studio Code) . entrambi i software ci consentono di effettuare HTTP request
step 2:
- Impostare postaman sul metodo GET e inserire l’URL https://jsonplaceholder.typicode.com/photos e premere invio
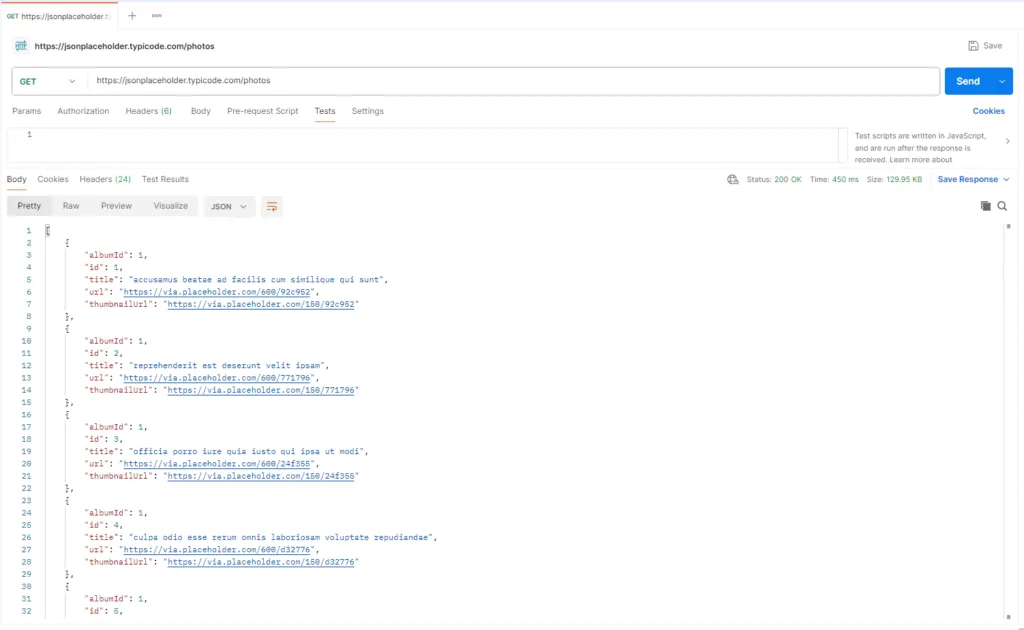
step3:
- analizziamo la risposta: status code 200 OK, per ogni album abbiamo il dettaglio delle immagini con ID, titolo e URL. ricerchiamo ad esempio l’immagine con id = 3622 per cui nel campo URL scriviamo https://jsonplaceholder.typicode.com/photos/3622 e premiamo invio visualizzandola sul browser al link indicato
Proviamo ora ad inserire un post. per fare questo scegliamo il metodo POST e nell’URL scriviamo https://jsonplaceholder.typicode.com/posts.
Ovviamente nel body dobbiamo scrivere i parametri:
{
"title": "mio post",
"body" : "questo è il mio primo post",
"userId" : 1
}Conclusione
Il livello di applicazione rappresenta il punto di incontro tra reti e software. Attraverso protocolli come HTTP, DNS e SMTP, e architetture come client-server e microservizi, è possibile realizzare i servizi Internet che utilizziamo quotidianamente.
Per lo studente di Sistemi e Reti, questi concetti costituiscono una base essenziale per comprendere lo sviluppo Web, le reti moderne e le tecnologie cloud.
Lascia un commento